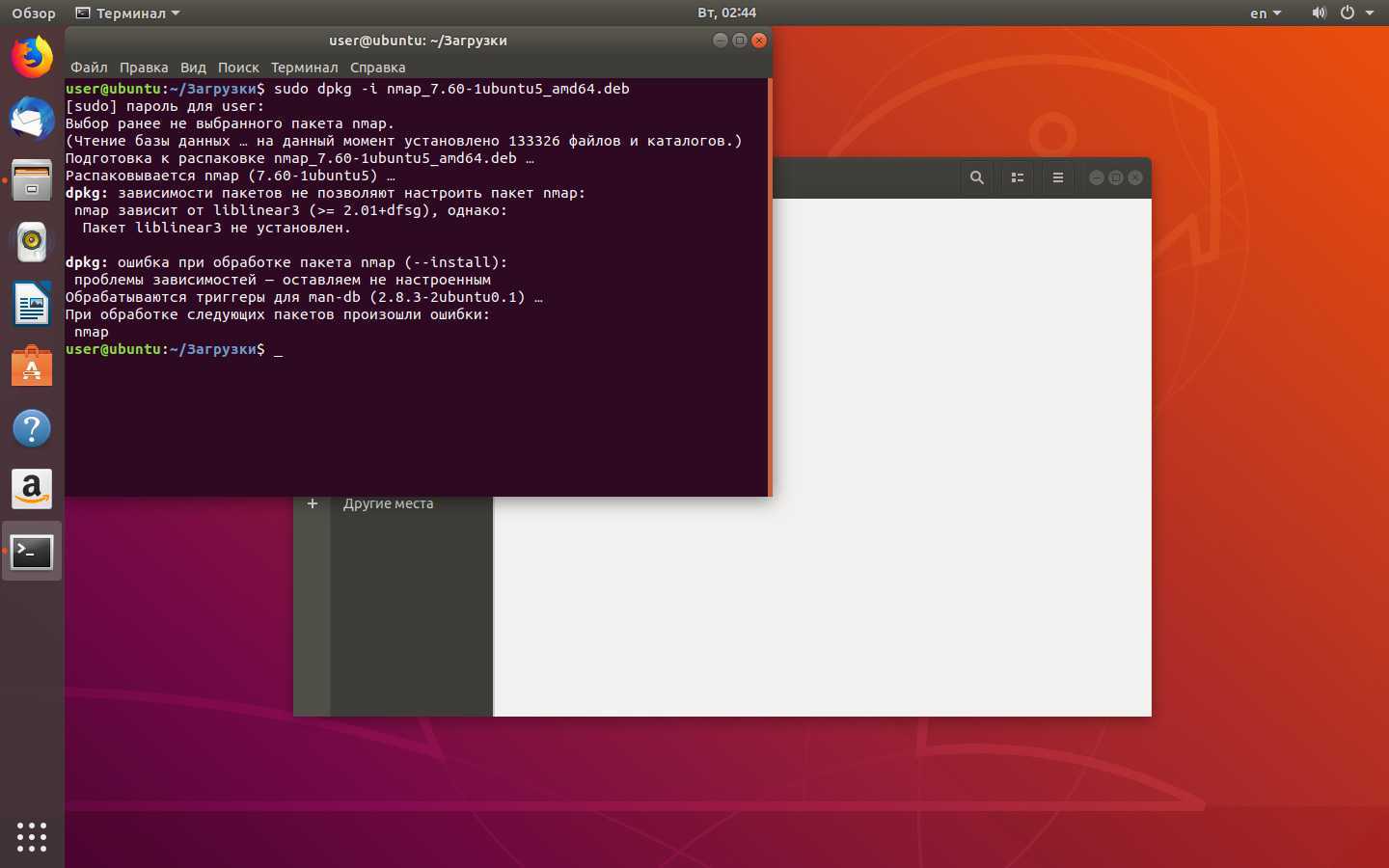
Разница между grep, egrep, fgrep, pgrep, zgrep
Различные переключатели grep исторически были включены в различные двоичные файлы. В современных системах Linux вы найдете эти переключатели доступными в команде base grep, но часто дистрибутивы поддерживают и другие команды.
Со страницы руководства для grep:
egrep является эквивалентом grep -E
Этот переключатель будет интерпретировать шаблон как расширенное регулярное выражение . Есть множество разных вещей, которые вы можете сделать с этим, но вот пример того, как выглядит использование регулярного выражения с grep.
Давайте найдем в текстовом документе строки, которые содержат две последовательные буквы «р»:
$ egrep p\{2} fruits.txt
или
$ grep -E p\{2} fruits.txt
fgrep является эквивалентом grep -F
Этот переключатель будет интерпретировать шаблон как список фиксированных строк и попытаться сопоставить любую из них. Это полезно, когда вам нужно искать символы регулярного выражения. Это означает, что вам не нужно экранировать специальные символы, как если бы вы использовали обычный grep.
$ fgrep $ License.txt There is a $100 free for commercial use.
pgrep — это команда для поиска имени запущенного процесса в вашей системе и возврата соответствующих идентификаторов процесса. Например, вы можете использовать его, чтобы найти идентификатор процесса демона SSH:
$ pgrep sshd
По функциям это похоже на простую передачу вывода команды ‘ps’ в grep.
Вы можете использовать эту информацию, чтобы убить работающий процесс или устранить проблемы со службами, работающими в вашей системе.
zgrep используется для поиска сжатых файлов по шаблону. Это позволяет вам искать файлы внутри сжатого архива без необходимости сначала распаковывать этот архив, в основном экономя вам дополнительный шаг или два.
$ zgrep apple fruits.txt.gz
zgrep также работает с tar-файлами, но кажется, что он говорит только о том, удалось ли найти совпадение.
$ zgrep apple fruits.tar.gz
Мы упоминаем об этом, потому что файлы, сжатые с помощью gzip, обычно являются архивами tar.
File and directory selection
| -a, —text | Process a binary file as if it were text; this is equivalent to the —binary-files=text option. |
| —binary-files=TYPE | If the first few bytes of a file indicate that the file contains binary data, assume that the file is of type TYPE. By default, TYPE is binary, and grep normally outputs either a one-line message saying that a binary file matches, or no message if there is no match. If TYPE is without-match, grep assumes that a binary file does not match; this is equivalent to the -I option. If TYPE is text, grep processes a binary file as if it were text; this is equivalent to the -a option. Warning: grep —binary-files=text might output binary garbage, which can have nasty side effects if the output is a terminal and if the terminal driver interprets some of it as commands. |
| -D ACTION,—devices=ACTION | If an input file is a device, FIFO or socket, use ACTION to process it. By default, ACTION is read, which means that devices are read as if they were ordinary files. If ACTION is skip, devices are silently skipped. |
| -d ACTION,—directories=ACTION | If an input file is a directory, use ACTION to process it. By default, ACTION is read, i.e., read directories as if they were ordinary files. If ACTION is skip, silently skip directories. If ACTION is recurse, read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -r option. |
| —exclude=GLOB | Skip files whose base name matches GLOB (using wildcard matching). A file-name glob can use *, ?, and as wildcards, and \ to quote a wildcard or backslash character literally. |
| —exclude-from=FILE | Skip files whose base name matches any of the file-name globs read from FILE (using wildcard matching as described under —exclude). |
| —exclude-dir=DIR | Exclude directories matching the pattern DIR from recursive searches. |
| -I | Process a binary file as if it did not contain matching data; this is equivalent to the —binary-files=without-match option. |
| —include=GLOB | Search only files whose base name matches GLOB (using wildcard matching as described under —exclude). |
| -r, —recursive | Read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -d recurse option. |
| -R,—dereference-recursive | Read all files under each directory, recursively. Follow all symbolic links, unlike -r. |
Difference between grep, egrep fgrep, pgrep, zgrep
Various grep switches were historically included in different binaries. On modern Linux systems, you will find these switches available in the base grep command, but it’s common to see distributions support the other commands as well.
From the man page for grep:
![]()
egrep is the equivalent of grep -E
This switch will interpret a pattern as an . There’s a ton of different things you can do with this, but here’s an example of what it looks like to use a regular expression with grep.
Let’s search a text document for strings that contain two consecutive ‘p’ letters:
$ egrep p\{2} fruits.txt
or
$ grep -E p\{2} fruits.txt
![]()
fgrep is the equivalent of grep -F
This switch will interpret a pattern as a list of fixed strings, and try to match any of them. It’s useful when you need to search for regular expression characters. This means you don’t have to escape special characters like you would with regular grep.
![]()
pgrep is a command to search for the name of a running process on your system and return its respective process IDs. For example, you could use it to find the process ID of the SSH daemon:
$ pgrep sshd
![]()
This is similar in function to just piping the output of the ‘ps’ command to grep.
![]()
You could use this information to kill a running process or troubleshoot issues with the services running on your system.
You can use zgrep to search compressed files for a pattern. It allows you to search the files inside of a compressed archive without having to first decompress that archive, basically saving you an extra step or two.



$ zgrep apple fruits.txt.gz
![]()
zgrep also works on tar files, but only seems to go as far as telling you whether or not it was able to find a match.
![]()
We mention this because files compressed with gzip are very commonly tar archives.
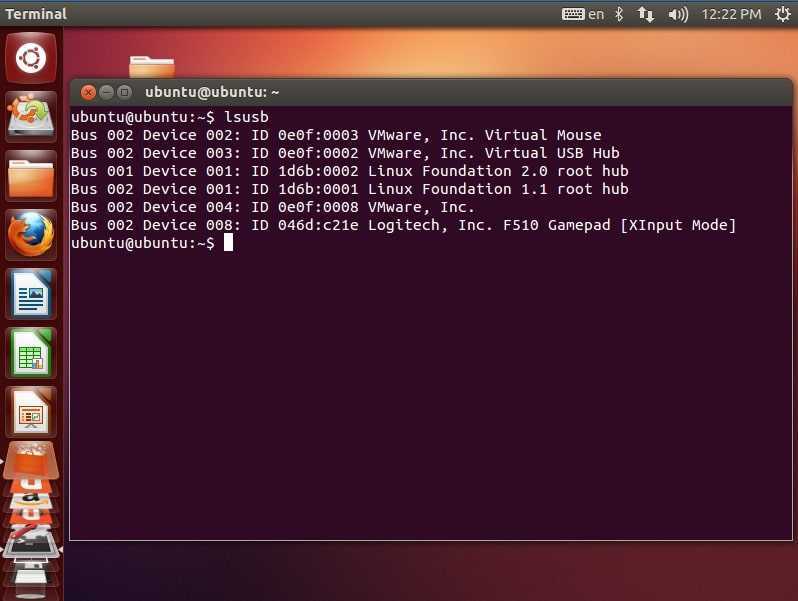
Как искать строку в файле с помощью GREP
![]()
Представьте, что у вас есть текстовый файл с названием books со следующими названиями детских книг:
- Робин Гуд
- Красная Шапочка
- Питер Пен
- Златовласка и три медведя
- Белоснежка и семь гномов
- Pinnochio
- Кот в мешке
- Три маленьких поросенка
- Граффало
- Чарли и шоколадная фабрика
Чтобы найти все книги со словом «The» в названии, вы должны использовать следующий синтаксис:
Будут возвращены следующие результаты:
В каждом случае слово «The» будет подсвечено.
В поиске учитывается регистр, поэтому, если бы у одного из заголовков было «the» вместо «The», он не был бы возвращен.
Чтобы игнорировать регистр, вы можете добавить следующий параметр:
Вы также можете использовать ключ -i следующим образом:
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
-regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
![]()
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);
![]()
Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.
Linux поиск по содержимому файлов командой grep
Часто возникают ситуации, что нужно найти какой-нибудь текст, но вы не помните, в каком файле/файлах он содержится. Секрет популярности — её мощь, она отдает возможность пользователям сортировать и фильтровать текст на основе сложных правил.
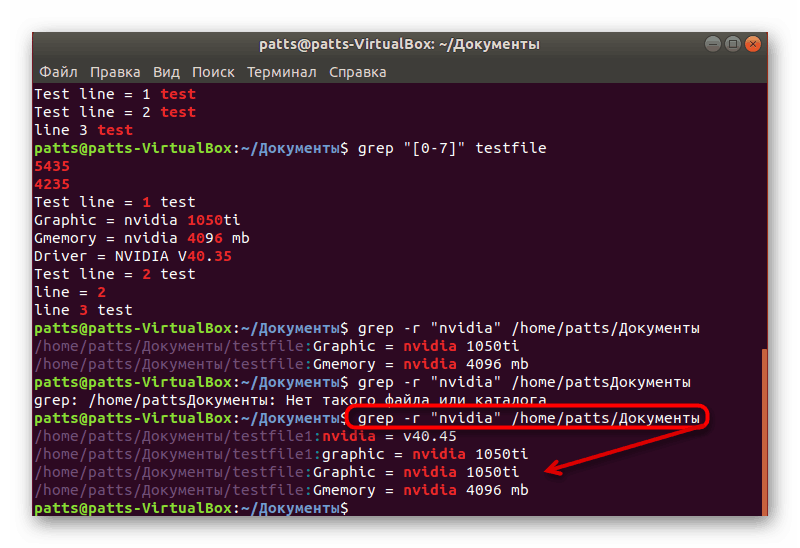
В этом варианте для поиска по содержимому файлов в каталоге можно использовать утилиту grep:
grep -r -n «text» /path
grep -r “Строчка для поиска”grep -rl $’xEFxBBxBF’
где:-n показывает строку, где был найден фрагмент;-r осуществляет розыск рекурсивно, в файлах в самом каталоге /path и в его подкаталогах;
Также можно приплюсовать опцию -C 3, чтобы видеть +- 3 строки вокруг (выше и ниже от найденной).
Дабы найти файл по его содержимому во всех Linux — подобных ОС, достаточно использовать утилиту find.
Linux поиск по содержимому файлов командой find
Своего рода швейцарским ножом в розыске файлов является команда find. Отметим, что она имеет множество опций, которые смогут кардинально изменять механизм поиска. Мы изложим лишь основные принципы, а с остальными способностями ознакомьтесь в справке по команде. Базовый принцип использования find состоит в указании папки поиска и опций. Например, выражение «find ~/ -name *.cpp» осуществит поиск файлов, имеющих продолжение «cpp» по всем каталогам, находящимся в личной директории пользователя.
![15 практических примеров использования команды grep в linux [rtfm.wiki]](https://lpfile.ru/wp-content/uploads/4/5/c/45c0f72741e35f82411a54f713b8839d.png)
/usr/bin/find /папка -type f -exec grep -H ‘строчка для поиска’ {} ;
Значение, указанное после опции -name, задает шаблон соотношения имени файла. Вы можете использовать опцию -type для указания типа файла, где в свойстве значений нужно использовать специальные буквы: d — директория, f — файл, l — символическая ссылка и т. д. Функции -user, -group и -size также довольно полезны. Их значениями являются имя пользователя, имя категории и размер файла в байтах.
find /var/www/ -name “file.conf”find /var/www/ -name “*.conf”
С поддержкою опции -exec каждому файлу, предназначенному для установки соответствия, можно добавить случайную обработку. Таким образом, появляется возможность осуществления поиска, как по имени файла, так и по охватываемому. Ниже приводится пример комбинирования команды find и grep за счет использования функции -exec.
find ~/ -name *.cppfind ~/ -name *.cpp -user ‘my-username’ -group ‘my-group’find ~/ -name ‘*.config’ -type f -exec grep ‘user’ {} ;find /home/ ( -name “*.php” -or -name “*.html” -or -name “*.js” )-exec grep -lHEi $’xEFxBBxBF’ {} ;
А возможно и еще проще
1.3, найди и xargs
При использовании параметра -exec команды find для обработки сопоставленных файлов команда find передает все сопоставленные файлы в exec для выполнения. Однако некоторые системы имеют ограничения по длине команд, которые могут быть переданы в exec, так что ошибка переполнения произойдет после того, как команда find выполняется в течение нескольких минут. Обычно это сообщение об ошибке «слишком длинный столбец параметров» или «переполнение столбцов параметров». Здесь полезна команда xargs, особенно когда она используется с командой find.
Команда find передает сопоставленные файлы команде xargs, а команда xargs одновременно получает только часть файлов, а не все, в отличие от параметра -exec. Таким образом, он может обработать первую часть файла, затем следующий пакет и т. Д.
В некоторых системах использование параметра -exec инициирует соответствующий процесс для обработки каждого сопоставленного файла вместо одновременного выполнения всех сопоставленных файлов в качестве параметров, поэтому в некоторых случаях будет слишком много процессов. Проблема снижения производительности, поэтому эффективность не высокая;
С помощью команды xargs существует только один процесс. Кроме того, при использовании команды xargs, получать ли все параметры сразу или в пакетном режиме, и количество параметров, полученных каждый раз, будет определяться в соответствии с параметрами команды и соответствующими настраиваемыми параметрами в ядре системы.
Давайте посмотрим, как команда xargs используется с командой find, и приведем несколько примеров.
Команда find используется в сочетании с exec и xargs, чтобы позволить пользователям выполнять почти все команды для соответствующих файлов.
2. Команда grep
grep (глобальный поиск по регулярному выражению (RE) и распечатка строки) — это мощный инструмент для поиска текста, который может искать текст с помощью регулярных выражений и распечатывать соответствующие строки ,
awk: извлечение и использование данных
awk — это специальный программируемый фильтр, который считывает и обрабатывает входные данные строку за строкой. Он располагает широким спектром встроенных функций:
- явные поля () и управление записями;
- функции (математические, построчная обработка и т. д.);
- синтаксический анализ и фильтрация регулярных выражений.
Этот фильтр также позволяет работать с переменными, циклы, условными обозначениями, массивами ассоциативных элементов, пользовательскими функциями.
Анатомия awk
В большинстве случае используется в качестве однострочной идиомы следующего вида:
или:
Где это:
- — выполнить определённое действие один раз перед чтением и обработкой входных данных;
- — выполнить действие для каждой строки входных файлов и/или , которые удовлетворяют шаблону или условию;
- — выполнить определённое действие один раз после прочтения и обработки входных данных.
В команде нужно указывать хотя бы один из вышеперечисленных разделов.
Шаблоны, условия и действия
Шаблон — это регулярное выражение, которое соответствует (или не соответствует) входной строке, например:
- — любая строка, содержащая New;
- — строка, начинающаяся с цифр;
- — строка, которая содержит определённые слова;
Условие — это булевое выражение, которое выбирает входные строки, например:
— строки, для которых третье поле больше, чем 1
Действие — это последовательность операций, например:
- — печать первого и последнего поля/столбца;
- — получить журнал второго поля/столбца;
- — получить суммарное значение.
При этом пользовательские функции могут быть определены и указаны в любом блоке действий.
Команда grep без опций и аргумента.
Если не указано имени файла, то команда обрабатывает стандартный ввод, например строки, набранные на клавиатуре:
$ grep кот у меня есть кошка,(Enter) вернее это кот,(Enter) вернее это кот, который умеет(Enter) который умеет ловить мышей.(Enter) (Ctrl+c)
В скобках показано, когда я нажимал клавишу Enter, чтобы перейти на новую строку. Одновременно, при нажатии Enter, программа выводила строки, содержащие ОБРАЗЕЦ (кот), отсюда и удвоение этих строк
Видно, что команда реагировала просто на сочетание букв, а не на слово «кот», иначе строка со словом «который» не попала бы в вывод.
Тут мы подошли к очень важному определению строки. Строкой команда grep (как и все остальные команды Юникс) считает все символы, находящиеся между двумя символами новой строки
Эти невидимые на экране символы возникают в тексте каждый раз, когда пользователь нажимает клавишу Enter. В Юниксовидных системах символ новой строки обозначается обратным слэшем с буквой n (\n). Таким образом, строка может быть любого размера, начиная с одного символа и до многомегабайтного текста. И команда grep честно выведет эту строку, при условии, что она содержит ОБРАЗЕЦ.
Как мне использовать grep для поиска файла в Linux?
Найдите /etc/passwd для пользователя boo, введите:
Примеры выходных данных::
foo:x:1000:1000:boo,,,:/home/boo:/bin/ksh
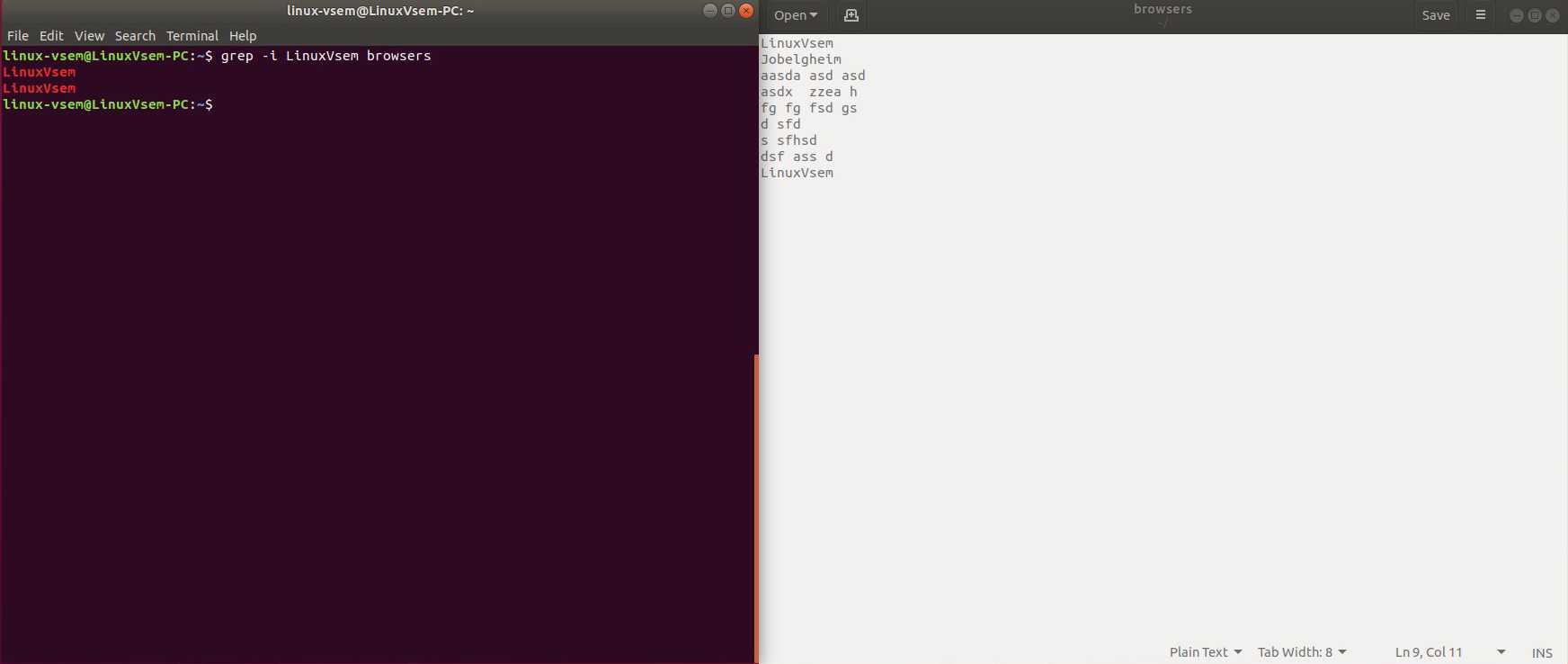
Мы можем использовать fgrep/grep тобы найти все строки файла, содержащие определенное слово. Например, чтобы перечислить все строки файла с именем address.txt в текущем каталоге, которые содержат слово “California” выполните:
Обратите внимание, что приведенная выше команда также возвращает строки, в которых “California” является частью других слов, например “Californication” или “Californian”. Следовательно, передайте -w параметр с помощью команды grep/fgrep чтобы получить только строки, в которых “California” включено как целое слово:
Вы можете заставить grep игнорировать регистр слов, то есть сопоставить boo, Boo, BOO и все другие комбинации с -i параметром. Например, введите следующую команду:. Последнийgrep -i «boo» /etc/passwd
Последнийgrep -i "boo" /etc/passwd
Параллельность в GNU
В данном случае речь идёт о параллельном выполнении задач из командной строки. В некотором смысле похожее на . Что по итогу это даёт?
- Позволяет обрабатывать параметры как независимые аргументы команды и выполнять параллельно команду.
- Осуществляет синхронизированный вывод — как если бы команды в Linux-терминале выполнялись последовательно.
- Обеспечивает настраиваемое количество параллельных заданий.
- Хорошо подходит для выполнения простых команд или скриптов на вычислительных узлах для использования многоядерной архитектуры.
Необходимо учитывать, что, возможно, потребуется специальная установка, так как по умолчанию это недоступно.
Примеры параллельного выполнения в GNU:
Для того, чтобы найти все html-файлы и переместить их в каталог:
Для того, чтобы удалить файл pict0000.jpg и заменить его на pict9999.jpg (здесь подразумевается одновременное выполнение 16 параллельных заданий):
Создание миниатюр для всех файлов изображений (требуется программное обеспечение imagemagick):
Загрузка из списка URL-адресов и отчёт о неудачных загрузках:
Для дополнительной информации можно ознакомиться с книгой GNU parallel 2018.