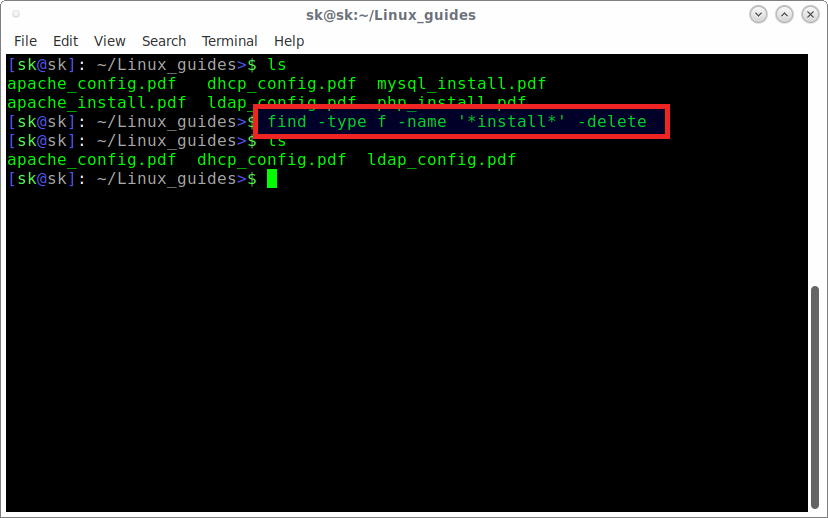
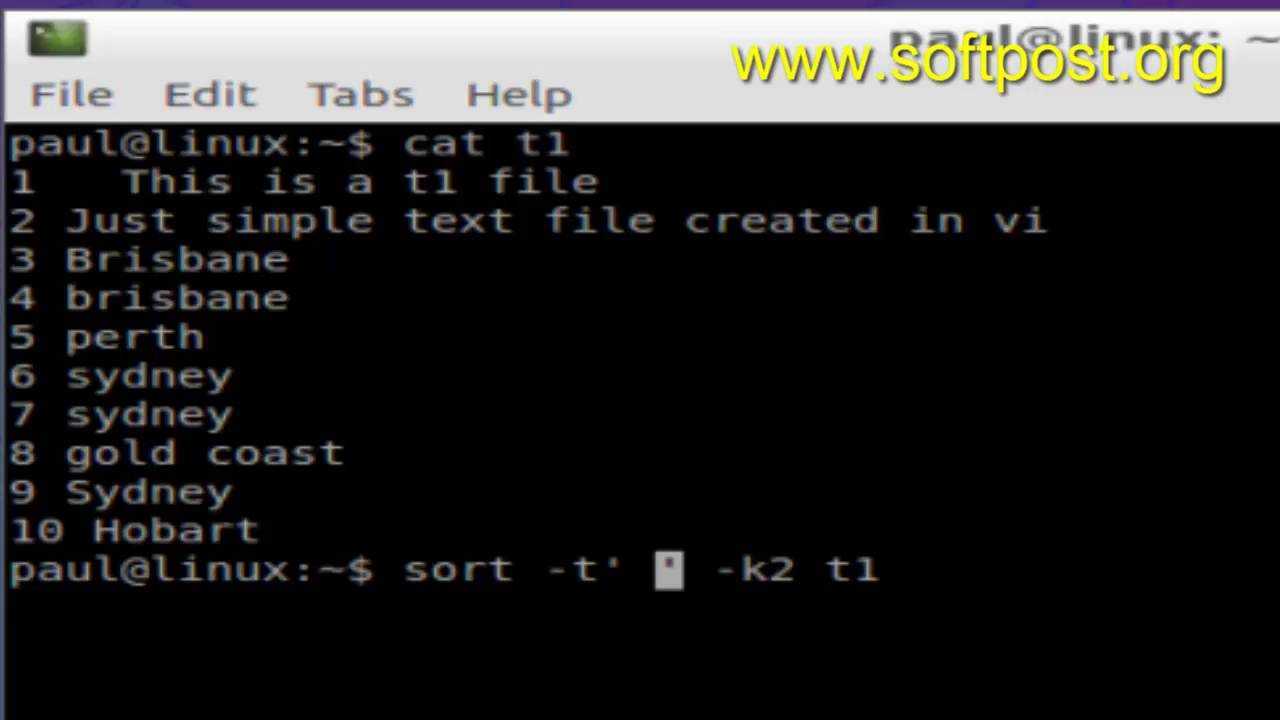
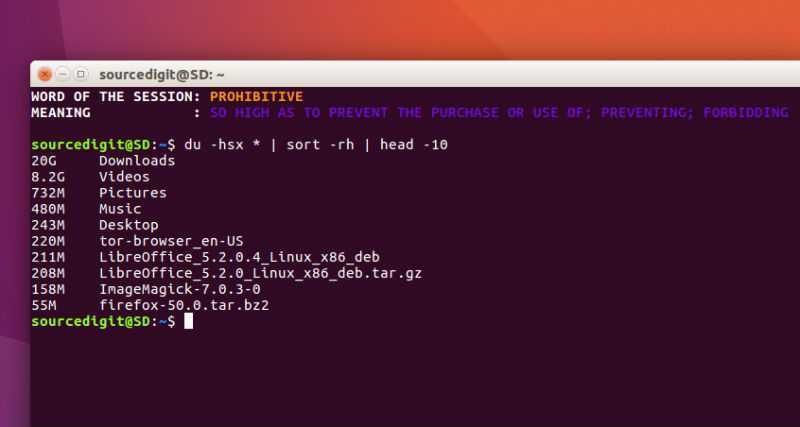
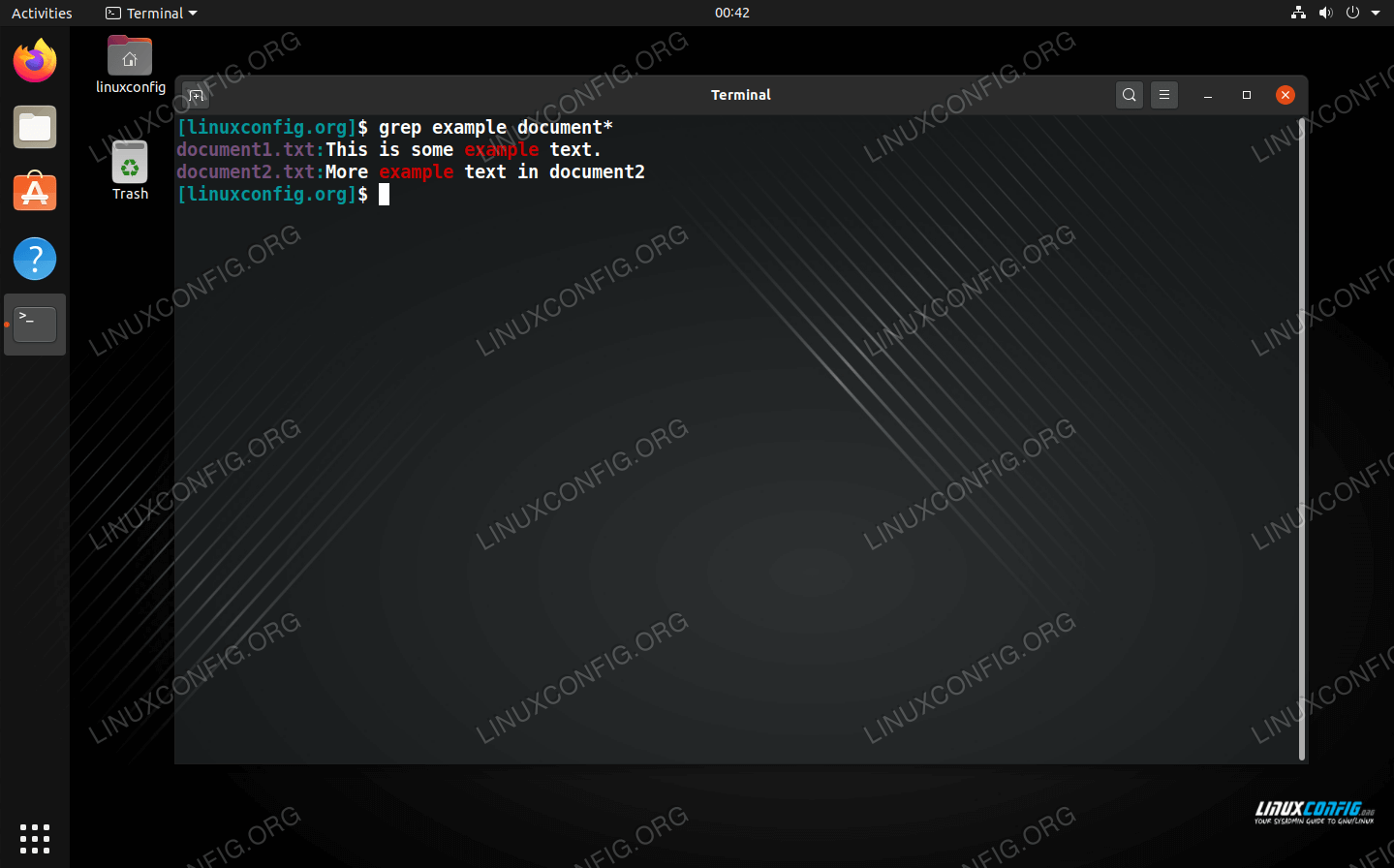
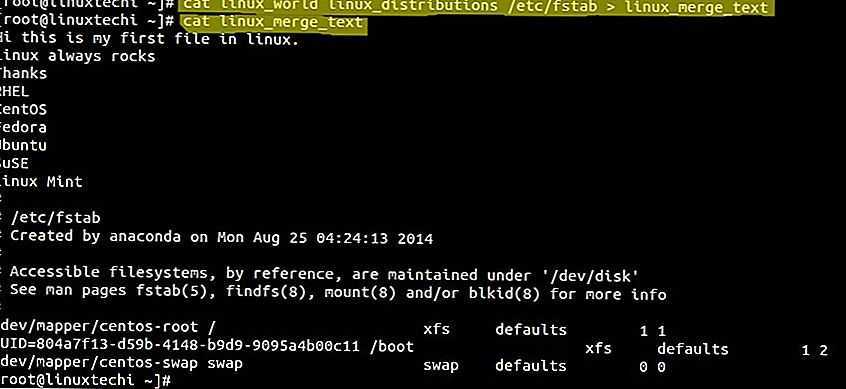
Рекурсивный поиск
Для рекурсивного поиска шаблона, используйте опцию (или ). Когда эта опция используется, будет выполняться поиск по всем файлам в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы перейти по всем символическим ссылкам , вместо этого используйте опцию (или ).
Вот пример, показывающий, как искать строку во всех файлах в каталоге:
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию, перейдите по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда вызывается из-за того, что файлы в каталоге Nginx являются символическими ссылками на файлы конфигурации внутри каталога.
Поиск полных слов
При поиске строки будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное не в словах), используйте параметр (или ).
Символов слова включают в себя буквенно — цифровые символы ( , и ) и подчеркивание ( ). Все остальные символы рассматриваются как несловесные символы.
Если вы выполните ту же команду, что и выше, включая опцию, команда вернет только те строки, которые включены в качестве отдельного слова.
Поиск без учета регистра
По умолчанию чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите с параметром (или ).
Например, при поиске без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра с использованием параметра , он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
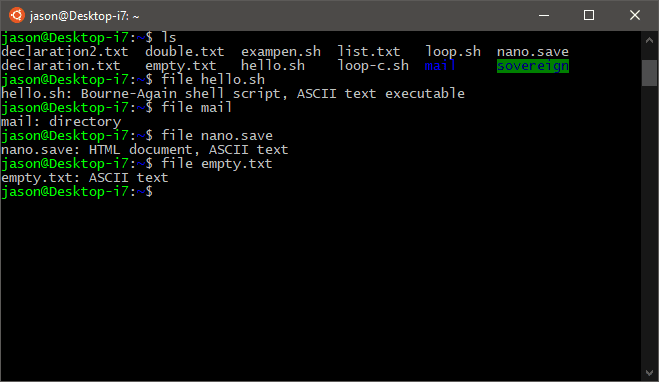
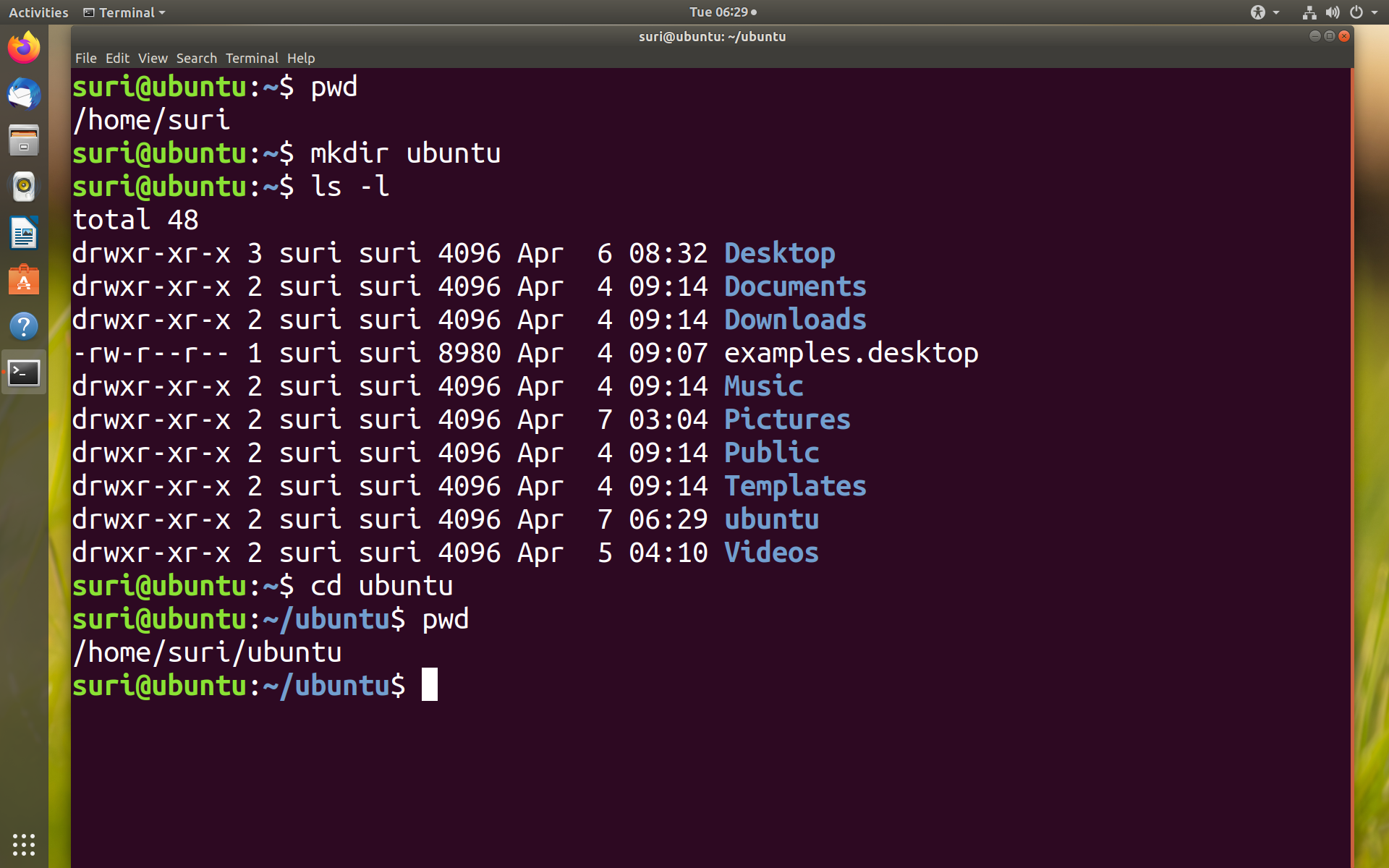
Просмотр текстового файла в Linux полностью
Чтобы вывести содержимое всего текстового файла, в Linux используют команду cat. Она отлично походит для вывода небольших текстовых файлов, к примеру, конфигурационных файлов. Синтаксис прост:
cat <путь_к_файлу/имя_файла>
Представьте, что надо посмотреть содержимое файла с названием myfile.txt:
cat myfile.txt
Также можно вместо имени прописать адрес (путь) к файлу:
cat /etc/passwd
Если нужно посмотреть несколько файлов сразу, это тоже не вызовет проблем:
Кроме того, при просмотре текстового файла в Linux мы можем отобразить номера строк. Для этого потребуется всего лишь использовать опцию -n:
cat -n file.txt
Команда nl функционирует аналогично команде cat с опцией -n, выводя номера строк в столбце слева.
nl file.txt
При необходимости вы можете сделать так, чтобы при выводе текстового файла в конце каждой строки отображался символ $:
cat -e test
Вывод будет следующим:
hello everyone, how do you do?$ $ Hey, am fine.$
Кроме cat, для вывода содержимого текстового файла в Linux используется команда tac. Её разница заключается в том, что она выводит содержимое файла в обратном порядке.
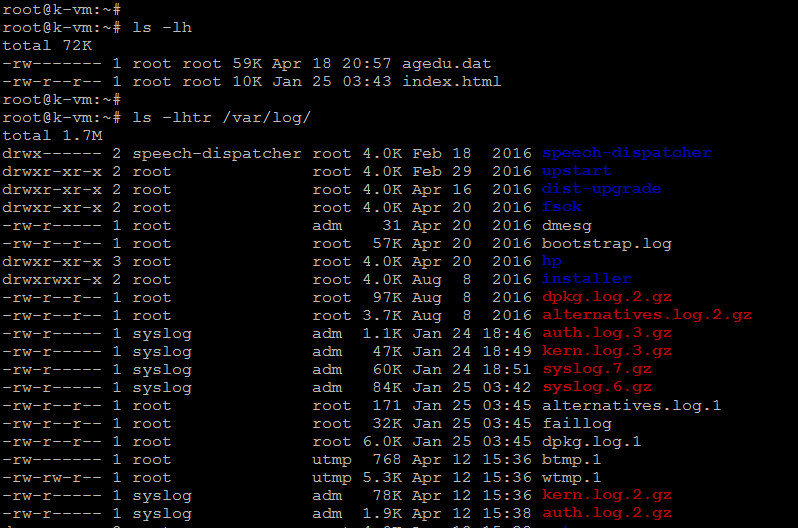
Листинг в длинном формате
Параметр -l (длинный список) заставляет ls предоставлять подробную информацию о каждом файле.
ls -l
![]()
Здесь много информации, так что давайте рассмотрим ее подробнее.
Первое, что отображает ls, — это общий размер всех файлов в списке. Затем каждый файл или каталог отображается в отдельной строке.
Первый набор из десяти букв и тире — это тип файла, а также владелец, группа и другие права доступа к файлу.
Самый первый символ представляет тип файла. Это будет один из:
-: обычный файл.b: специальный файл блока.c: специальный символьный файл.d: Каталог.l: символическая ссылка.n: сетевой файл.p: именованный канал.s: розетка.
Следующие девять символов представляют собой три группы по три символа, отображаемых подряд. Каждая группа из трех представляет разрешения на чтение, запись и выполнение в указанном порядке. Если разрешение предоставлено, будет присутствовать r, w или x. Если разрешение не предоставлено, отображается дефис -.
Первый набор из трех символов — это разрешения для владельца файла. Второй набор из трех разрешений предназначен для членов группы, а последний набор из трех разрешений — для других.
Иногда разрешение на выполнение для владельца представлено буквой s. Это Setuid немного. Если он присутствует, это означает, что файл выполняется с привилегиями владельца файла, а не пользователя, выполняющего файл.
Разрешение на выполнение для группы также может быть s. Это Setgid немного. Когда это применяется к файлу, это означает, что файл будет выполнен с привилегиями группы владельца. При использовании с каталогом любые файлы, созданные внутри него, будут получать свои групповые разрешения из каталога, в котором они создаются, а не от пользователя, который создает файл.
Разрешение на выполнение для остальных иногда может быть представлено буквой t. Это липкий кусочек. Обычно применяется к каталогам. Если он установлен, независимо от прав записи и выполнения, установленных для файлов в каталоге, только владелец файла, владелец каталога или пользователь root могут переименовывать или удалять файлы в каталоге.
Обычно липкий бит используется в таких папках, как «/ tmp». Это доступно для записи всем пользователям компьютера. Бит залипания в каталоге гарантирует, что пользователи и процессы, запущенные пользователями, могут переименовывать или удалять только свои временные файлы.
Мы видим липкий бит в каталоге «/ tmp»
Обратите внимание на использование параметра -d (каталог). Это заставляет ls сообщать подробную информацию о каталоге
Без этой опции ls будет сообщать о файлах внутри каталога.
ls -l -d /tmp
![]()
Число после разрешений — это количество жестких ссылок на файл или каталог. Для файла это обычно один, но если создаются другие жесткие ссылки, это число будет увеличиваться. В каталоге обычно есть как минимум две жесткие ссылки. Один является ссылкой на себя, а другой — его записью в родительском каталоге.
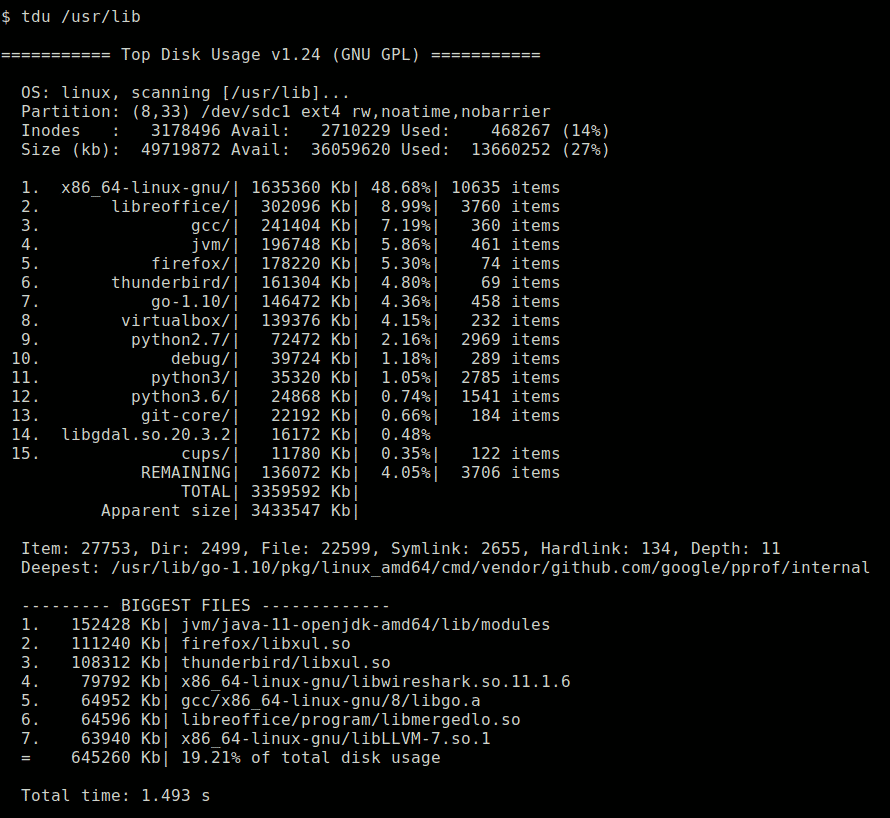
Далее отображаются имя владельца и группа. За ними следует размер файла и дата последнего изменения файла. Наконец, дается имя файла.
Просматриваем начало или конец файла в Linux
Порой, нам не нужно выводить содержимое всего файла и мы хотим, к примеру, посмотреть лишь несколько строчек лога. Такое часто бывает, если мы подозреваем, что в начале или в конце конфигурационного файла есть ошибки. Для решения данного вопроса у нас существуют команды head и tail (как вы уже догадались, это голова и хвост).
Команда head по умолчанию показывает лишь 10 первых строчек в текстовом файле в Linux:
head /etc/passwd
Вот, что мы увидим:
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/false daemon:x:2:2:daemon:/sbin:/bin/false adm:x:3:4:adm:/var/adm:/bin/false lp:x:4:7:lp:/var/spool/lpd:/bin/false sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt news:x:9:13:news:/var/spool/news:/bin/false uucp:x:10:14:uucp:/var/spool/uucp:/bin/false
Кстати, тут мы тоже можем открыть сразу несколько текстовых файлов в Linux одновременно. Вот просмотр сразу двух файлов:
head /etc/passwd /etc/shadow
Если же вас не интересуют все 10 строчек, то, как и в случае с cat, можно использовать опцию –n, цифрой указывая число строк к выводу:
head -n5 /var/log/emerge.log
В итоге мы вывели только пять строк:
1394924012: Started emerge on: Mar 15, 2014 22:53:31 1394924012: *** emerge --sync 1394924012: === sync 1394924012: >>> Synchronization of repository 'gentoo' located in '/usr/portage'... 1394924027: >>> Starting rsync with rsync://212.113.35.39/gentoo-portage
По правде говоря, букву n можно и не использовать, достаточно просто передать цифру:
head -5 /var/log/emerge.log
Кстати, выводить содержимое текстового файла в Linux можно не построчно, а посимвольно. Давайте зададим число символов, которое нужно вывести (используем опцию -с):
head -c45 /var/log/emerge.log
Итак, выводим 45 символов:
1394924012: Started emerge on: Mar 15, 2014 2
Не верите, что их действительно 45? Проверить можно командой wc:
head -c45 /var/log/emerge.log | wc -c 45
С «головой» разобрались, давайте поговорим про «хвост». Очевидно, что команда tail работает наоборот, выводя десять последних строк текстового Linux-файла:
tail /var/log/emerge.log
Количество строк при выводе тоже можно менять. Однако в tail есть такая полезная опция, как -f. С её помощью содержимое текстового файла будет постоянно обновляться, в результате чего вы станете видеть изменения сразу (постоянно открывать и закрывать файл не придётся). Это весьма удобно, если вы хотите просматривать логи Linux в реальном времени:
tail -f /var/log/emerge.log
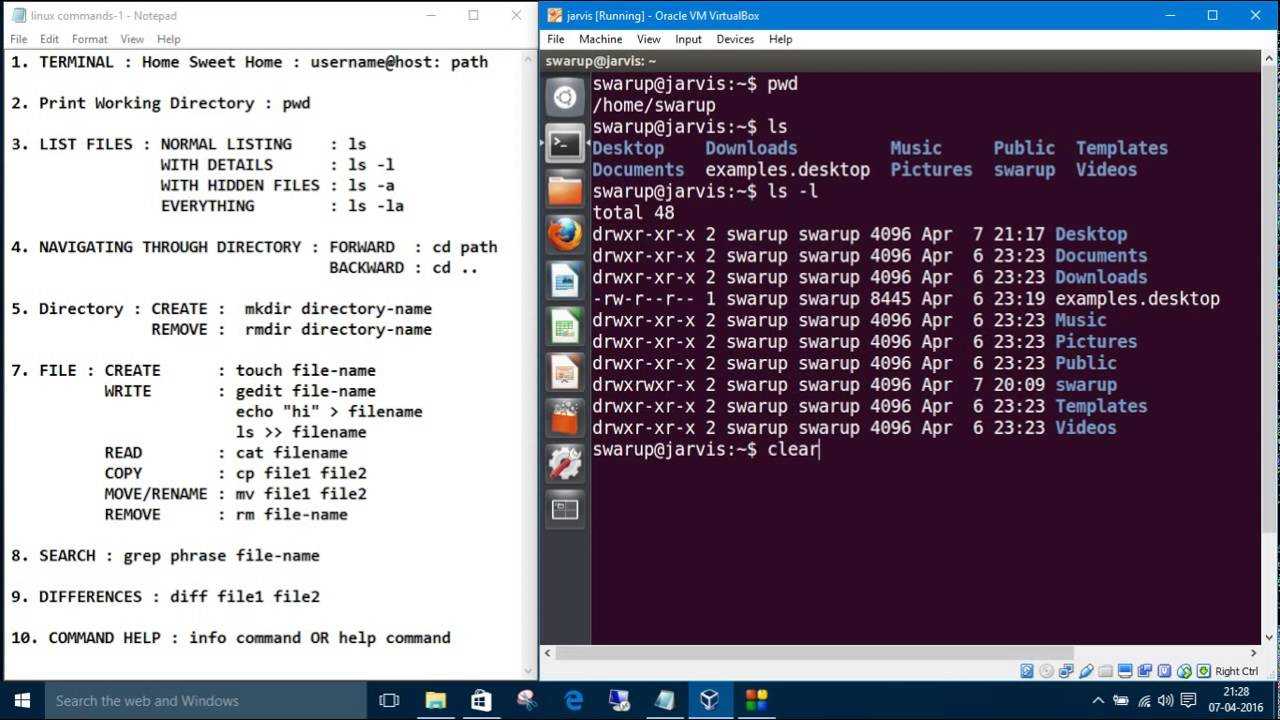
Как использовать команду uniq
Существуют различные параметры и флаги, которые вы можете использовать с uniq. Некоторые из них являются базовыми и выполняют простые операции, такие как печать повторяющихся строк, в то время как другие предназначены для опытных пользователей, которые часто работают с текстовыми файлами в Linux.
Базовый синтаксис
Базовый синтаксис команды uniq:
… где option – это флаг, используемый для вызова определенных методов команды, input – это текстовый файл для обработки, а output – это путь к файлу, в котором будет храниться вывод.
Выходной аргумент является необязательным и может быть пропущен. Если пользователь не указывает входной файл, uniq берет данные из стандартного вывода в качестве входных. Это позволяет пользователю передавать uniq по конвейеру с другими командами Linux .
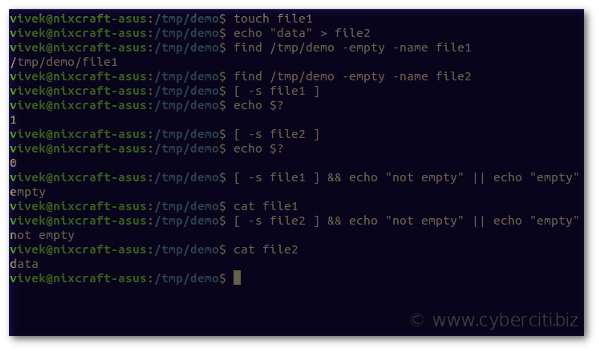
Пример текстового файла
Мы будем использовать текстовый файл duplicate.txt в качестве входных данных для команды.
Обратите внимание, что мы уже отсортировали этот текстовый файл с помощью команды sort. Если вы работаете с другим текстовым файлом, вы можете отсортировать его с помощью следующей команды:
Удалить повторяющиеся линии
Основное использование uniq – удаление повторяющихся строк из ввода и печать уникального вывода.
Выход:
![]()
Обратите внимание, что система не отображает второе вхождение строки. Это текстовый файл
Кроме того, вышеупомянутая команда печатает только уникальные строки в файле и не влияет на содержимое исходного текстового файла.
Подсчет повторяющихся строк
Чтобы вывести количество повторяющихся строк в текстовом файле, используйте флаг -c с командой по умолчанию.
Выход:
![]()
Система отображает количество строк в текстовом файле. Вы можете видеть, что строка This is a text file встречается в файле два раза. По умолчанию команда uniq чувствительна к регистру.
Печатать только повторяющиеся строки
Чтобы печатать только повторяющиеся строки из текстового файла, используйте флаг -D . -D означает Дубликат .
Система отобразит вывод следующим образом.
Пропуск полей при проверке дубликатов
Если вы хотите пропустить определенное количество полей при сопоставлении строк, вы можете использовать флаг -f с командой. -F означает поле .
Рассмотрим следующий текстовый файл fields.txt .
Чтобы пропустить первое поле:
Выход:
Вышеупомянутая команда пропустила первое поле (IP-адреса и имена ОС) и сопоставила второе слово (TCP и FS). Затем он отображал первое вхождение каждого совпадения в качестве вывода.
Игнорировать символы при сравнении
Как и при пропуске полей, вы также можете пропускать символы. Флаг -s позволяет указать количество символов, которые следует пропускать при сопоставлении повторяющихся строк. Эта функция помогает, когда данные, с которыми вы работаете, представлены в виде следующего списка:
Чтобы игнорировать первые два символа (нумерацию списков) в файле list.txt :
Выход:
![]()
В выводе выше первые два символа были проигнорированы, а остальные были сопоставлены с уникальными строками.
Проверьте количество первых N символов на наличие дубликатов
Флаг -w позволяет проверять на наличие дубликатов только фиксированное количество символов. Например:
Вышеупомянутая команда будет соответствовать только первым двум символам и будет печатать уникальные строки, если таковые имеются.
Выход:
![]()
Удалить чувствительность к регистру
Как упоминалось выше, uniq чувствителен к регистру при сопоставлении строк в файле. Чтобы игнорировать регистр символов, используйте параметр -i с командой.

![7 способов сравнения файлов по содержимому в windows или linux [айти бубен]](https://lpfile.ru/wp-content/uploads/5/9/0/5909e92c4f00b9aadec684a9eb7781eb.jpeg)
Вы увидите следующий результат.
![]()
Обратите внимание, что в выводе выше uniq не отображал строки DO CATCH THIS и THIS IS A TEXT FILE
Отправить вывод в файл
Чтобы отправить вывод команды uniq в файл, вы можете использовать символ перенаправления вывода ( > ) следующим образом:
При отправке вывода в текстовый файл система не отображает вывод команды. Вы можете проверить содержимое нового файла с помощью команды cat .
Вы также можете использовать другие способы отправки вывода командной строки в файл в Linux .
Linux урок 7. Команды Man, info, ключ —help. Справочная документация команд в Linux.
844
17
2
00:09:00
10.09.2020
Команды Man, info, ключ help.
Справочная документация команд в Linux.
=
Команда man (manual — руководство)
Выводит страницу документации запрашиваемой команды.
В качестве аргумента передается имя_команды.
Ман-страницы, или просто маны — это классическая
форма справочной документации UNIX и Linux.
На практике некоторые страницы руководств
не были написаны или устарели.
Тем не менее, маны остаются первым местом,
куда следует обращаться за помощью.
Синтаксис:
man имя_команды
Пример:
man cat
Построчное пролистывание:
-стрелочки вверх/вниз
-вверх, клавиша: y
-вниз, клавиша: e или ENTER
Постраничное пролистывание:
w — вверх к началу документа
z или ПРОБЕЛ — вниз к концу страницы
Справка по навигации, клавиша: h,
Вернуться в документацию, клавиша: q
Выход из ман-страницы, клавиша: q
Заголовки man странице:
NAME — имя команды, функция которую она
показывает(Например: поиск файлов)
SYNOPSYS — Синтаксис команды.
-Параметры без скобок являются ОБЯЗАТЕЛЬНЫМИ
-Параметры в квадратных скобках []
являются НЕ ОБЯЗАТЕЛЬНЫМИ(опциональные расширения
или просто опции)
DISCRIPTION — Описание программы и ее ключей.
EXAMPLES — Пример использования команды
AUTHOR — Разработчик программы
REPORTING BUGS — Сообщать об ошибках в программе.
COPYRIGHT — Авторские права на программу,
лицензии под которой она распространяется.
SEE ALSO — Дополнительная информация.
Обратить внимание на cat
CAT(1) — число 1 указывает на раздел
к которому относится данная страница. Самый последний мануал
🤍
Самый последний мануал
🤍
=
Команда info
Гипертекстовый сборник (в тексте есть ссылки по
которым можно перемещаться)
Синтаксис
info имя_команды
Пример:
info cat
Построчное пролистывание:
-стрелочки вверх/вниз
Перемещение по ссылкам:
-переместить курсор в подчеркнутый текст
начинающийся с *, нажать ENTER
Перемещение по статьям:
p -вверх к началу документа
n -вниз к концу документа
Выход из документации:
q
=
Команда help, но лучше использовать ее как ключ
help -данный ключ, позволяет получать краткую
справку по команде. Информация видна, во время
написания следующей команды.
Пример:
cat help
cat help|less
Примеры команды grep в Linux и Unix
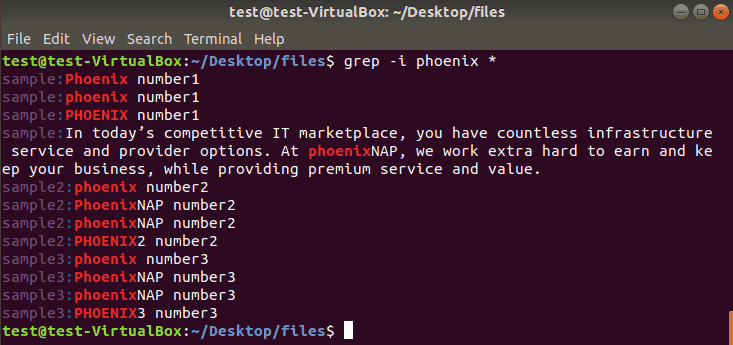
Ниже приведены некоторые стандартные команды grep, объясненные с примерами, которые помогут вам начать работу с grep в Linux, macOS и Unix:
- Найдите любую строку, которая содержит слово в имени файла в Linux: grep 'word' filename
- Выполните поиск слова ‘bar’ без учета регистра в Linux и Unix: grep -i 'bar' file1
- Найдите все файлы в текущем каталоге и во всех его подкаталогах в Linux по слову httpd: grep -R 'httpd' .
- Найдите и отобразите общее количество раз, когда строка ‘nixcraft’ появляется в файле с именем frontpage.md:: grep -c 'nixcraft' frontpage.md
Давайте подробно рассмотрим все команды и параметры.
Синтаксис
Синтаксис grep следующий:
grep 'word' filename fgrep 'word-to-search' file.txt grep 'word' file1 file2 file3 grep 'string1 string2' filename cat otherfile | grep 'something' command | grep 'something' command option1 | grep 'data' grep --color 'data' fileName grep -options pattern filename fgrep -options words file |
grep ‘word’ filename
fgrep ‘word-to-search’ file.txt
grep ‘word’ file1 file2 file3
grep ‘string1 string2’ filename
cat otherfile | grep ‘something’
command | grep ‘something’
command option1 | grep ‘data’
grep —color ‘data’ fileName
grep pattern filename
fgrep words file
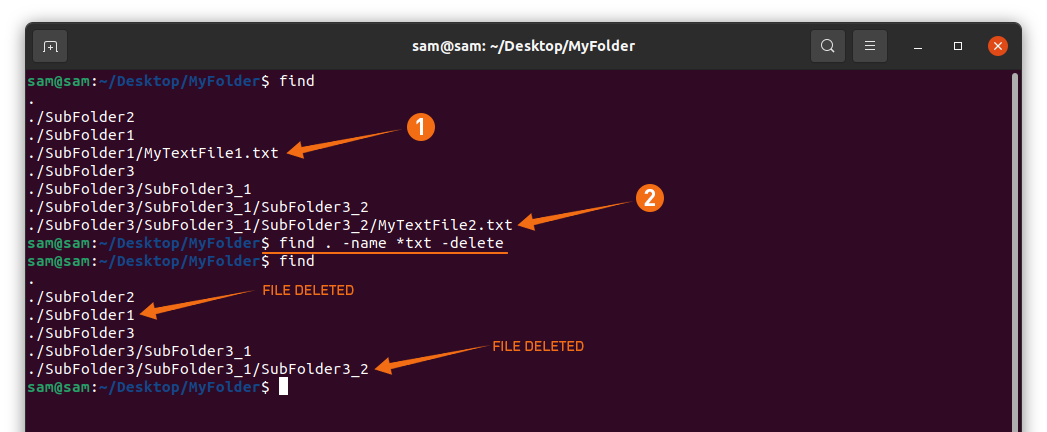
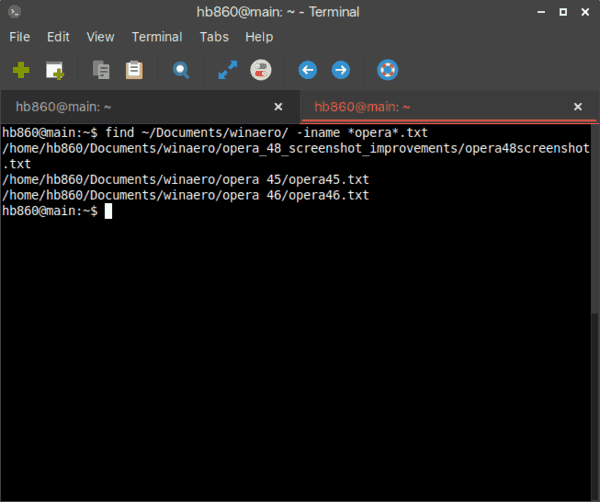
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите с параметром (или ). Когда используется этот параметр, будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
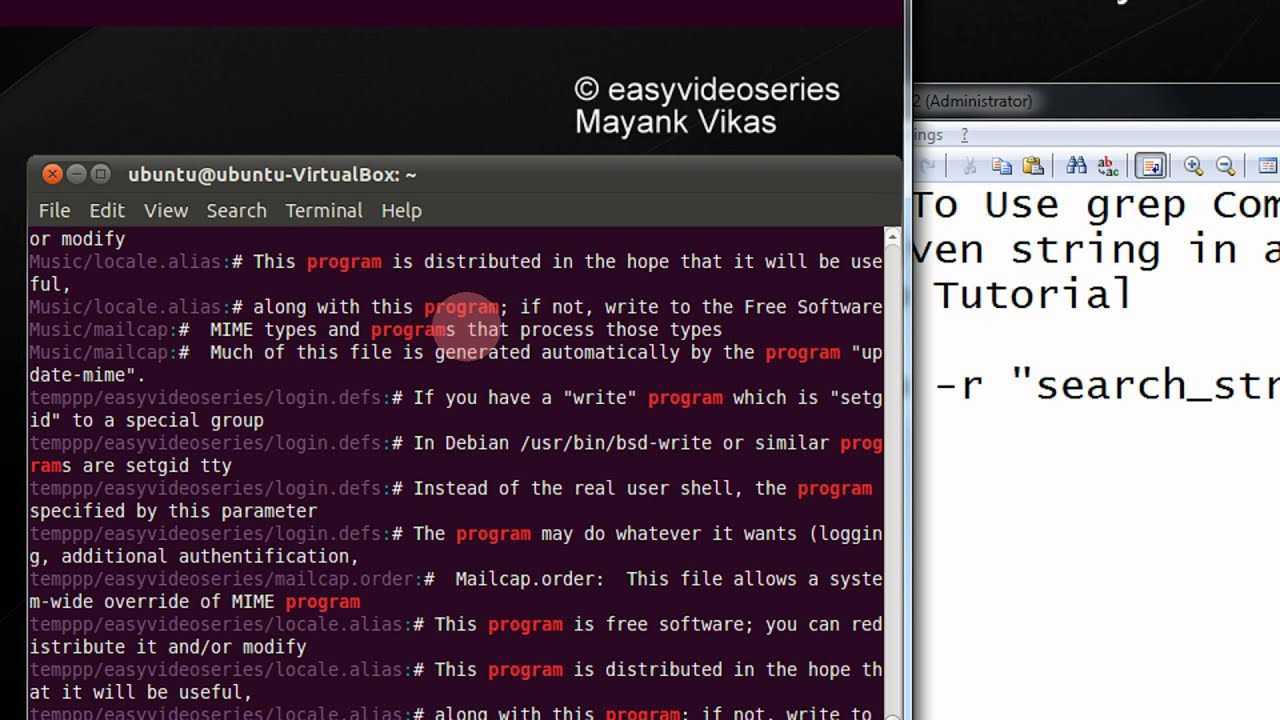
Чтобы следовать по всем символическим ссылкам , вместо используйте параметр (или ).
Вот пример, показывающий, как искать строку во всех файлах внутри каталога :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию , будет следовать по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда вызывается с потому что файлы внутри каталога с Nginx являются символическими ссылками на файлы конфигурации внутри каталога с
Способ 8. Сравнение двух текстовых файлов утилитой comm в Unix
Unix утилита comm входит в стандартную поставку всех Unix- дистрибутивов, таких как FreeBSD, GNU/Linux (пакет GNU Coreutils) и другие.
Программа comm используется для построчного сравнения двух текстовых файлов с отсортированными по алфавиту строками, в соответствии с используемой локалью. Для сортировки можно использовать утилиту sort.
При вызове без параметров рассматриваемая утилита будет выводить строки в трех столбцах: первый столбец будет содержать строки, присутствующие лишь в файле 1, второй столбец — строки, присутствующие лишь в файле 2, а третий столбец — строки, присутствующие в обоих файлах. Утилита поддерживает параметры -1, -2 и -3, позволяющие не выводить столбцы под соответствующими номерами. Статус завершения работы утилиты не зависит от результата распределения строк по столбцам; в случае успешного распределения строк утилита завершает работу с нулевым статусом, в случае возникновения любой ошибки — с ненулевым.
Базовый синтаксис команды выглядит следующим образом:
$ comm параметры <файл 1> <файл 2>
Параметры запуска: -1 Подавить вывод первой колонки; -2 Подавить вывод второй колонки; -3 Подавить вывод третьей; -i Нечувствительное к регистру сравнение строк.
Примеры запуска утилиты comm для сравнения двух файлов по содержимому:
- comm -1 file1 file2 сравнить содержимое двух файлов, не отображая строки принадлежащие файлу ‘file1’
- comm -2 file1 file2 сравнить содержимое двух файлов, не отображая строки принадлежащие файлу ‘file2’
- comm -3 file1 file2 сравнить содержимое двух файлов, удаляя строки встречающиеся в обоих файлах
-
запуск comm с предварительной сортировкой
comm <(sort file1.txt) <(sort file2.txt)
-
В текстовых файлах часто встречаются нежелательные символы, такие как символ возврата каретки, символ конца строки в стиле Windows, символов пробела или табуляции. Самым надежным вариантом было бы отфильтровать все такие нежелательные символы, а поскольку данные являются строго числовыми, это довольно легко сделать, например, с помощью sed (пример вырезания нежелательных символов
sed 's///g' < input > output
. В итоге получаем такую команду:
comm <(sed 's///g' file1.txt | sort) <(sed 's///g' file2.txt | sort)