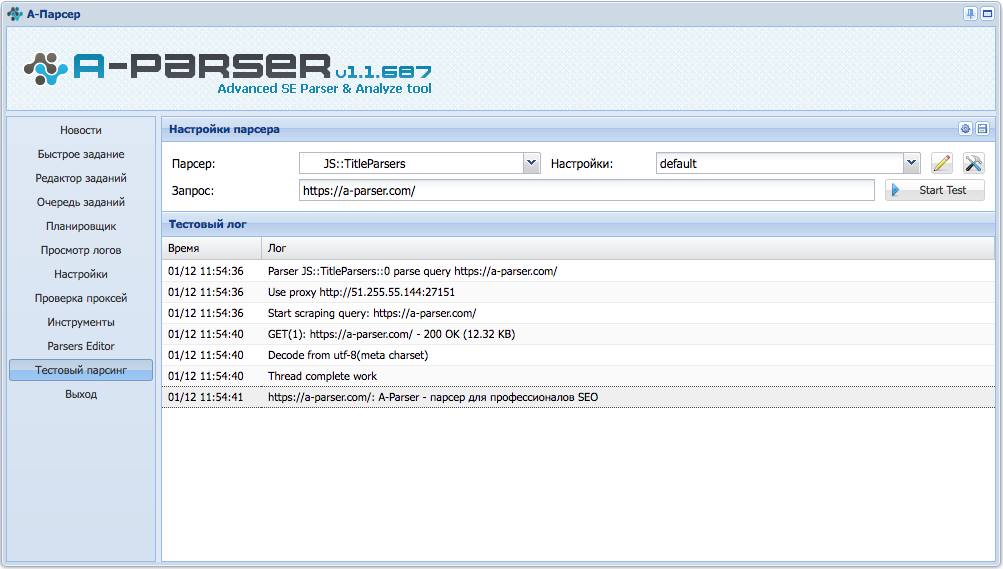
Как скрапить YouTube с помощью Python, Requests, и Beautiful Soup
Будучи программистом, вы можете разработать собственный веб-скрапер, но это не так просто, как может показаться.
Во-первых, вы должны понимать, что скрапер, написанный для пары страниц, отличается от того, что потребуется для обработки сотен или тысяч.
Простой скрапер разбирает 20 страниц (а может, и больше), не встречая никаких преград. Но если вы будете скрапить намного больше страниц, вам придётся иметь дело с блокировщиками IP и капчами. Anti-scraping технологий много, но обход капчей и блокировщиков решает большую часть проблем.
Реализовать такой скрапер проще всего на Python, так как этот язык предоставляет библиотеки и фреймворки, которые упростят разработку.
То, какие библиотеки вам понадобятся, в большинстве случаев зависит от типа данных, которые нужно собрать. Если выполнение скриптов и JavaScript-рендеринг не нужны, подойдут Requests и Beautiful Soup, Scrapy тоже будет хорошим выбором. Но если требуется выполнить js-скрипты, чтобы вытянуть данные, лучшим решением будет Selenium.
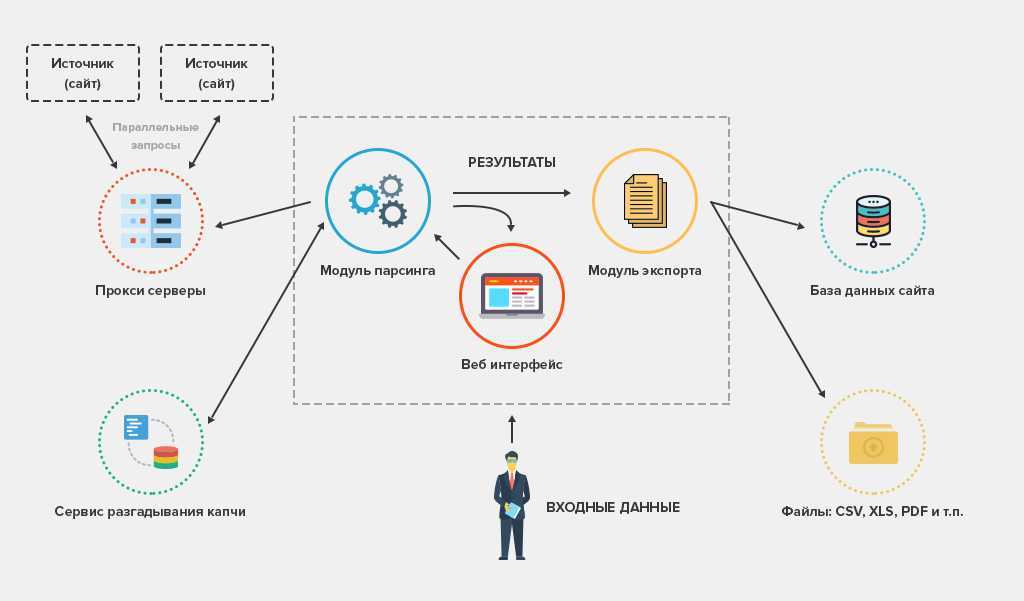
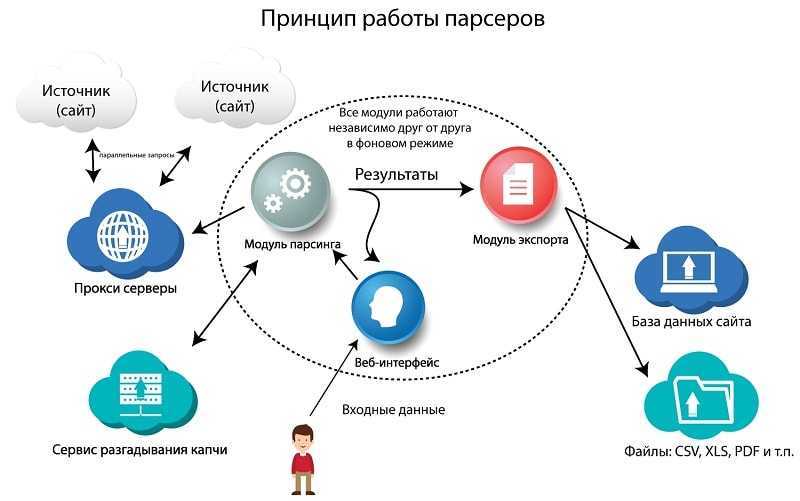
Разрабатывая веб-скрапер для YouTube, нужно обеспечить избегание блокировки IP и прохождение капчей. Скрыть IP и избежать блокировки вам помогут прокси, а расправиться с капчами при их срабатывании — решатели капчей.
Если вы собираетесь обработать большое количество страниц, а процесс требуется ускорить, стоит задуматься о применении многопоточности. Ниже представлен простой скрапер YouTube, который принимает URL видео и возвращает количество его просмотров.
import requests
from bs4 import BeautifulSoup
class YoutubeScraper:
def __init__(self, url):
self.url = url
def scrape_video_count(self):
content = requests.get(self.url)
soup = BeautifulSoup(content.text, "html.parser")
view_count = soup.find("div", {"class": "watch-view-count"}).text
return view_count
url = "https://www.youtube.com/watch?v=VpTKbfZhyj0"
x = YoutubeScraper(url)
x.scrape_video_count()
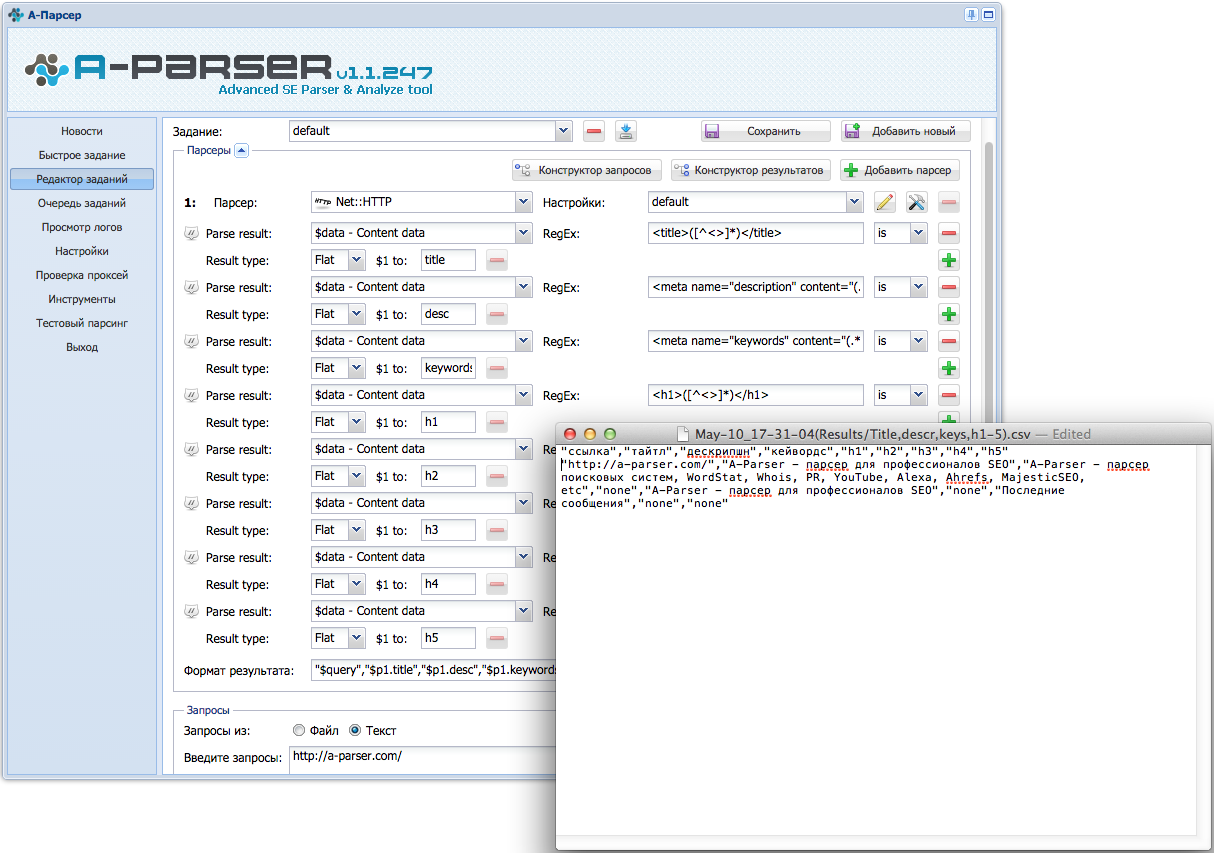
Программа: извлечение данных с веб-сайта Flipkart
В этом примере мы удалим цены, рейтинги и название модели мобильных телефонов из Flipkart, одного из популярных веб-сайтов электронной коммерции. Ниже приведены предварительные условия для выполнения этой задачи:
- Python 2.x или Python 3.x с установленными библиотеками Selenium, BeautifulSoup, Pandas.
- Google – браузер Chrome.
- Веб-парсеры, такие как html.parser, xlml и т. д.
Шаг – 1: найдите нужный URL.
Первым шагом является поиск URL-адреса, который вы хотите удалить. Здесь мы извлекаем детали мобильного телефона из Flipkart. URL-адрес этой страницы: https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off.
Шаг 2: проверка страницы.
Необходимо внимательно изучить страницу, поскольку данные обычно содержатся в тегах. Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Шаг – 3: найдите данные для извлечения.
Извлеките цену, имя и рейтинг, которые содержатся в теге «div» соответственно.
Шаг – 4: напишите код.
from bs4 import BeautifulSoupas soup
from urllib.request import urlopen as uReq
# Request from the webpage
myurl = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
uClient = uReq(myurl)
page_html = uClient.read()
uClient.close()
page_soup = soup(page_html, features="html.parser")
# print(soup.prettify(containers))
# This variable held all html of webpage
containers = page_soup.find_all("div",{"class": "_3O0U0u"})
# container = containers
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price.text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings.text)
#
# #
# # print(len(containers))
# print(container.div.img)
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratings\n"
f.write(headers)
for container in containers:
product_name = container.div.img
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container.text.strip()
rating_container = container.find_all("div",{"class":"niH0FQ"})
ratings = rating_container.text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee
split_price = add_rs_price.split("E")
final_price = split_price
split_rating = str(ratings).split(" ")
final_rating = split_rating
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.close()
Выход:
Мы удалили детали iPhone и сохранили их в файле CSV, как вы можете видеть на выходе. В приведенном выше коде мы добавили комментарий к нескольким строкам кода для тестирования. Вы можете удалить эти комментарии и посмотреть результат.
Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Iwantsoft Free
Работает на ОС: WindowsFree режим: с ограниченным функционалом для частного использования
Простой и удобный в настройке софт для наблюдения за рабочим компьютером, либо за домашним. Наблюдение за компьютером выполняется через просмотр активности с использованием функции блокирования нежелательной или запрещенной информации. Шпион для удаленного слежения за ПК внедряется в систему на глубоком уровне, его работа не видна, он никак не влияет на взаимодействие юзера с машиной.
Дистанционное наблюдение позволяет следить за чужим компьютером в режиме online. Отслеживается весь запускаемый софт и онлайн ресурсы. Имеется возможность составить список нежелательных ресурсов, которые будут блокироваться, либо при открытии которых по ftp будет направляться уведомление со сводкой. Скачав и установив на компьютер этот софт, можно использовать его в том числе как кейлоггер для ПК – он фиксирует все нажатия клавиш и систематизирует их. То есть вы будете знать, где поисковый запрос, где фраза из мессенджера, а где строка текста из рабочего документа.
Настройка решения и мониторинг за компьютерами сотрудников также включает фиксирование и систематизацию данных по рабочей эффективности с функцией time-treker (хотя и достаточно ограниченного по функционалу). Сводки, сохраняемые в сетевые папки или отправляемые через ftp на электронную почту руководителю, не дают комплексного представления о работе отделов и компании в целом. Поэтому данное решение для отслеживания активности и работы на компьютере не подойдет крупным компаниям с серьезным подходом.
Лучшие скраперы YouTube
Если же вы не программист, вы можете найти готовые скраперы для YouTube (вам не придется написать ни строчки кода). Впрочем, не все из них «non-code» – некоторые потребуют от вас определённых навыков. Ниже представлены лучшие программы, которые можно использовать для скрапинга YouTube.
Octoparse
- Цена: от $75/месяц
- Бесплатные пробные версии: 14 дней бесплатно с ограничениями
- Формат данных CSV, Excel, JSON, MySQL, SQLServer
- Платформы: Cloud, Desktop
Если вам надоели блокировки, представляем вам Octoparse — скрапер, который поможет справиться с проверками безопасности даже на самых продвинутых сайтах. Пожалуй, это один из лучших веб-скраперов на рынке. Вы можете использовать его для добычи общедоступных текстовых данных с YouTube.
Octoparse облегчает процесс скрапинга, ведь в нём уже есть готовые шаблоны для работы с популярными сайтами, что избавляет вас от необходимости с нуля прописывать все правила для определённых сайтов.
ScrapeStorm
- Цена: от $49.99 /месяц
- Бесплатные пробные версии: Starter plan бесплатно с ограничениями
- Формат данных: TXT, CSV, Excel, JSON, MySQL, Google Sheets, и т.д.
- Платформы: Desktop
ScrapeStorm – один из наиболее универсальных скраперов, так как его можно использовать для скрапинга почти всех сайтов (и YouTube в том числе). Поддерживается он всеми наиболее популярными операционными системами. Также доступна версия на базе облачных технологий.
Этот инструмент использует искусственный интеллект, который в большинстве случаев автоматически распознаёт данные и парсит их без вмешательства человека.
Data Miner
- Цена: от $19/месяц
- Бесплатные пробные версии: стартовый план (500 страниц) бесплатно
- Формат данных: CSV, Excel
- Платформы: браузеры Chrome и Edge
Data Miner – расширение для браузера с поддержкой Chrome и Microsoft Edge. Data Miner также может использоваться для скрапинга YouTube. С таким скрапером можно не бояться обнаружения, потому что он умеет скрывать подозрительное поведение.
Data Miner не выдаст ваши данные, а ещё он поддерживает более 15000 сайтов. Здесь есть бесплатный тариф, который, возможно, идеально вам подойдёт, если вы не планируете скрапить в крупных масштабах.
Что вам точно понравится в Data Miner, – это более 50000 предварительно созданных запросов, которые помогут вам выполнить работу одним щелчком мыши. Data Miner заполняет формы, упрощает автоматический парсинг и обеспечивает поддержку пользовательского парсинга.
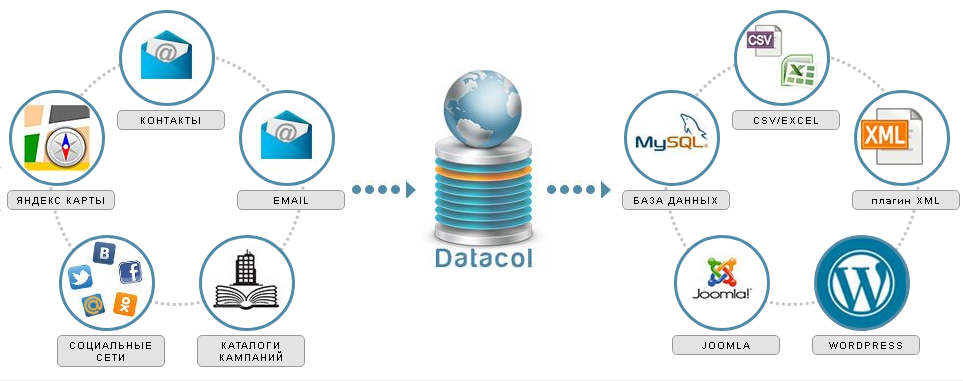
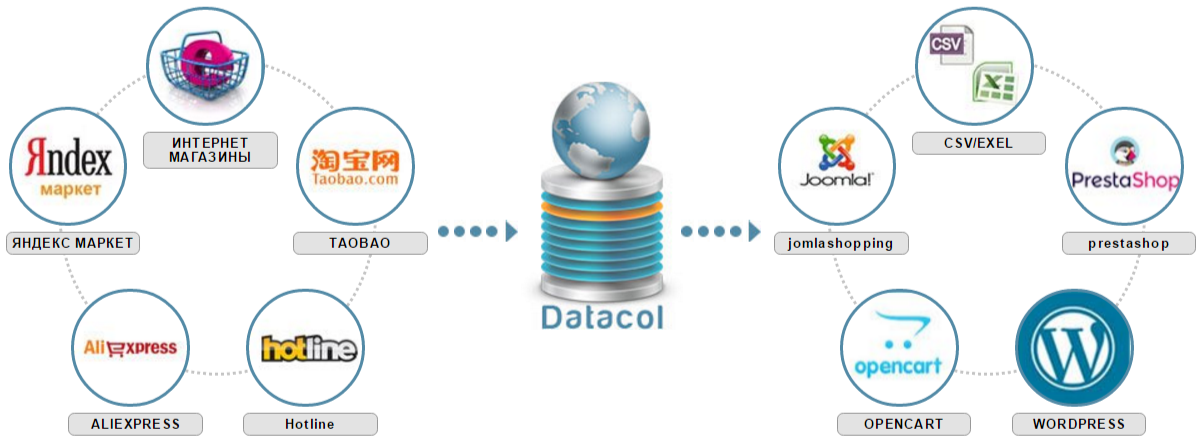
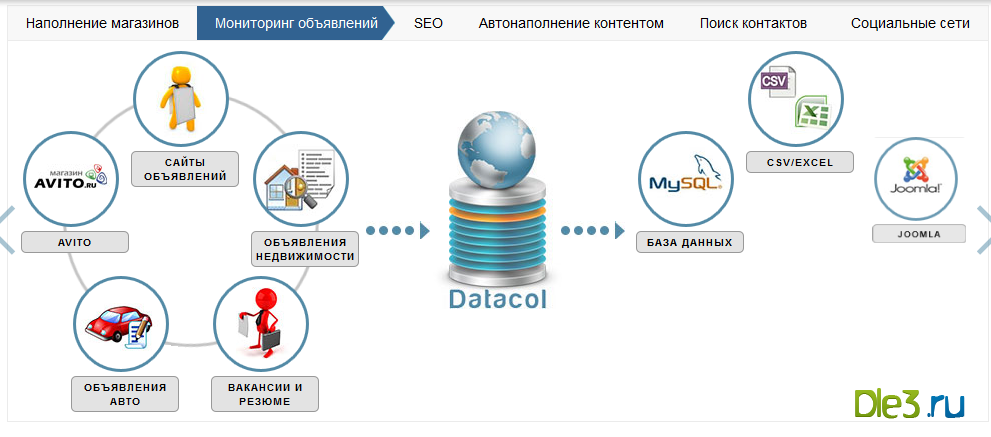

ParseHub
- Ценаот $149/месяц
- Бесплатные пробные версии: Desktop бесплатна с некоторыми ограничениями
- Формат данныхExcel, JSON
- Платформы: Cloud, Desktop
ParseHub это ещё одно устанавливаемое программное обеспечение, которое можно использовать для скрапинга. ParseHub не является специализированным инструментом для парсинга YouTube, как и другие в этом списке. Тем не менее, он предоставляет средства для добычи общедоступных данных на YouTube, и на данный момент является одним из лучших инструментов на этом рынке.
Десктопная версия ParseHub бесплатна (с некоторыми ограничениями). А вот за облачную версию придётся платить, но она предлагает большое количество дополнительных функций.
Helium Scraper
- Цена: лицензия от $99
- Бесплатные пробные версии: весь функционал предоставляется бесплатно на 10 дней
- Формат данных: CSV, Excel, XML, JSON, SQLite
- Платформы: Desktop
Ещё один отличный инструмент, который можно применить для скрапинга видео, комментариев, рейтингов и других общедоступных данных на YouTube. Чтобы использовать Helium Scraper, его нужно установить на компьютер.
Большое преимущество этого скрапера – широкий спектр функций, которые позволяют парсить в крупных масштабах. К числу этих функций относятся:
- запланированный скрапинг,
- способность быстро собирать данные со сложной структурой,
- система обнаружения аналогичных элементов,
- ротация прокси,
- экспорт собранных данных в различные форматы и многое другое.
Скрапинг Сайта Авито За ПАРУ МИНУТ С Помощью Python
8473
317
17
00:13:11
27.07.2020
5 ЛУЧШИХ Советов Которые Помогут ПРАВИЛЬНО Выучить Python: 🤍
Код программы: 🤍
Ссылка на группу ВКонтакте: 🤍
Канал PyLounge: 🤍
По вопросам сотрудничества и предложений: peoplesdreamer🤍gmail.ru
Music: 🤍
Информации в интернете с каждым днём всё больше и больше. Все эти данные так или иначе приходится собирать. Они могут нам понадобиться для сбора статистики, анализа данных или даже создания датасетов, которые будут использоваться в машинном обучении. Именно для такого сбора информации с веб сайтов придумали скрапинг. Штука очень болезная и мощная. Поэтому сегодня я расскажу про это на примере скрапинга данных с сайта Авито.
Я долго занимаюсь программированием, в частности программирование на языке Python. Я много чего узнал за это время, и мне есть, чем поделиться со зрителями моего канала. Здесь выходят разнообразные ролики, касающиеся IT-тематики и программирования.
Подписывайся, будем узнавать что-то новое и работать вместе! Погнали!
6.3. Screaming Frog SEO Spider
Screaming Frog SEO Spider — это кроулер веб-сайтов, который позволяет улучшить SEO своего сайта, извлекая данные и проверяя их на наличие распространенных проблем SEO.
Вы можете загрузить и проанализировать 500 URL-адресов бесплатно или приобрести лицензию, чтобы получить доступ к расширенным функциям. Анализ результатов проводится в режиме реального времени.
С помощью Screaming Frog SEO Spider можно находить битые ссылки, проверять перенаправления, анализировать заголовки страниц и метаданные, находить повторяющийся контент, извлекать данные с помощью , просматривать URL-адреса заблокированные файлом и директивами сервера, создавать XML-карты сайтов, планировать расписание проверок, пользоваться многими другими полезными функциями.
Пост-эксплуатация
Пост-эксплуатация — это то, что можно сделать с целевой системой после того, как удалось найти уязвимость и выполнить какой-то участок кода на целевой системе.
Основные паттерны, по которым работают злоумышленники предполагают:
- получить доступ на выполнение (желательно в реальном времени)
- изучение данных, хранящихся на сервере
- перехват данных, которых нет на системе сейчас, но они могут появиться в будущем
- организация перманентного доступа к целевой системе
Злоумышленник может получать информацию о скомпрометированной системе, анализируя:
- конфигурацию системы (логин и пароль к БД в исходных кодах)
- конфигурацию веб-сервера (например httpd.conf, .htaccess)
- исходные коды приложения (ищем уязвимости, анализируя логику приложения)
- доступы к окружению (находясь внутри сети может быть проще попасть на соседние сервера)
- базы данных (и аутентификационная информация,к другим системам, хранящаяся в них)
Получение паролей из хеша
Чаще всего пароли хранят в виде хешей. Но есть способы получить пароль, имея его хеш.
Один из самых известных онлайн-брутфорсеров паролей: John the Ripper.
Может быть использован, например, так:
Организация перманентного доступа
Самый простой способ — создать своего пользователя (желательно замаскировав его под системного).
Другой вариант — бинарные бекдоры, которые кладутся на систему и организуется их периодическое выпролнение (через cron или при каждом вызове любой частой команды, например ls).
Если удалось получить доступ под пользователем веб-сервера, можно сделать веб-бекдор, например положив куда-либо на вебсервере скрипт, позволяющий выполнять произвольные действия.
Самый жесткий вариант — патч ядра операционной системы, включение бекдора туда.
Объясним на квадратах
Допустим, у вас есть сервис, на котором пользователи смотрят цветные квадраты. В интерфейсе есть кнопки с цветами, в которые можно покрасить фигуры. Вы сделали для сервиса и статический сайт, и одностраничное приложение:
![]()
На первый взгляд, разницы между сайтом и приложением нет. Чтобы её заметить, нажмём на кнопку с другим цветом.
![]()
Здесь становится заметно, что сайт и одностраничное приложение ведут себя по-разному:
![]()
![]()
![]()
![]()
Страница сайта обновится целиком. Получается, мы говорим серверу: «Привет, сделай-ка квадраты зелёными». Он говорит: «Хорошо. Но ещё вот вам снова шапка сайта и подвал, а также кнопки и метаданные». И отдаёт целиком новый HTML-файл.
В одностраничном приложении обновится только цвет квадратов. Браузер отправляет серверу запрос, тот возвращает нужный параметр, квадраты красятся, всё остальное остаётся неизменным.
Как смягчается веб-скрапинг?
Реальность такова, что нет никакого способа, чтобы остановить веб-скреп. Учитывая достаточное количество времени, находчивый веб-скрейпер может очищать весь веб-сайт с открытым доступом, страница за страницей. Это является результатом того факта, что любая информация, видимая внутри веб-браузера, должна быть загружена рендером.
Распространенный метод смягчения требует встраивания содержимого в мультимедийные объекты, такие как изображения. Поскольку содержимое не существует в строке символов, копирование содержимого является гораздо более сложным, требующим оптического распознавания символов (OCR) для извлечения данных из файла изображения. Это также может затруднить веб-пользователям копирование содержимого, например адреса или номера телефона, с веб-сайта вместо запоминания или повторного ввода.
Все содержимое, которое может видеть посетитель, должно быть передано на компьютер посетителя, и любая информация, к которой посетитель может получить доступ, может быть очищена.
Можно предпринять усилия, чтобы ограничить количество веб-скрейпа, которое может произойти. Существует 3 основных метода ограничения воздействия усилий по очистке данных:
- Запросы на ограничение скорости. Для человека, просматривающего серию веб-страниц на веб-сайте, скорость взаимодействия с веб-сайтом довольно предсказуема. Например, у компании никогда не будет человека, просматривающего 100 веб-страниц в секунду. Компьютеры, с другой стороны, могут делать запросы на порядки быстрее, чем человек, и начинающие скрейперы данных могут использовать методы необузданного скрейпа, чтобы попытаться очень быстро очистить весь веб-сайт. По скорости, ограничивающей максимальное количество запросов, которые конкретный IP-адрес может сделать в течение заданного окна времени. Веб-сайты могут защитить себя от эксплуататорских запросов и ограничить количество скрейпа данных, которые могут произойти в определенном окне.
- Изменение разметки HTML через регулярные промежутки времени. Программное обеспечение для скрейпа данных опирается на последовательное форматирование, чтобы эффективно просматривать содержимое веб-сайта и анализировать, и сохранять полезные данные. Одним из способов прерывания этого рабочего процесса является регулярное изменение элементов HTML-разметки, что усложняет последовательную очистку. Путем вложения HTML-элементов или изменения других аспектов разметки простые усилия по очистке данных будут затруднены или сорваны. Для некоторых веб-сайтов, каждый раз, когда веб-страница оказывается в той или иной форме изменения защиты контента рандомизированы и реализованы, в то время как другие изменяют свой веб-сайт иногда, чтобы предотвратить долгосрочные усилия по очистке данных.
- Использовать «капчу» для больших объемов запросов. В дополнение к использованию решения для ограничения скорости, еще одним полезным шагом в замедлении скрейпа контента является требование, чтобы посетитель веб-сайта ответил на задачу, которую трудно преодолеть компьютеру. В то время как человек может разумно ответить на вопрос, безголовый браузер, участвующий в очистке данных, скорее всего, не сможет. Другие задачи на основе javascript могут быть реализованы для тестирования функциональности браузера.
Безголовый браузер — это тип веб-браузера, похожий на Chrome или Firefox, но по умолчанию он не имеет визуального пользовательского интерфейса, что позволяет ему двигаться намного быстрее, чем обычный веб-браузер. По существу, работает на уровне командной строки, безголовый браузер может избежать визуализации всего веб-приложения. Скрейперы данных пишут сценарии для использования безголовых браузеров для более быстрого запроса данных, так как нет человеческого просмотра каждой очищаемой страницы.

Параметры домена
Yandex Индексация
1 910
По данному тесту найдена история!
В графике изменения за 1 год 3 месяца (начиная с апр. 2018). Доступно на платных тарифах.
Тарифы и цены
Подробнее
Описание
Примерное количество проиндексированных страниц в выдаче Яндекса можно посмотреть через оператор site:, что мы и делаем. Он покажет результат поиска по URL сайта, но точную цифру страниц в индексе выдавать не обязан.
Точные данные Яндекс отображает в Яндекс.Вебмастере. График изменений количества находится в разделе «Индексирование сайта» — «Страницы в поиске».
Данные теста были получены 29.08.2021 05:15
Google Индексация
3 140
По данному тесту найдена история!
В графике изменения за 1 год 3 месяца (начиная с апр. 2018). Доступно на платных тарифах.
Тарифы и цены
Подробнее
Описание
Сколько страниц сайта Google точно проиндексировал, узнать невозможно. Поисковик не ведет базу данных по URL-адресам.
Примерное количество страниц в выдаче покажет оператор site:, на который мы ориентируемся. Число может быть искажено страницами, которые запрещены к индексу в robots.txt, но попали в выдачу из-за внешних ссылок на них.
Чуть более точное количество покажет раздел «Статус индексирования» в Google Search Console, но и эти данные могут быть искажены из-за применения фильтров.
Данные теста были получены 29.08.2021 05:15
Фильтр АГС
Фильтр не найден
Описание
Примерное количество проиндексированных страниц в выдаче Яндекса можно посмотреть через оператор site:, что мы и делаем. Он покажет результат поиска по URL сайта, но точную цифру страниц в индексе выдавать не обязан.
Точные данные Яндекс отображает в Яндекс.Вебмастере. График изменений количества находится в разделе «Индексирование сайта» — «Страницы в поиске».
Данные теста были получены 29.08.2021 05:15
Google безопасный просмотр
Сайт безопасен.
Описание
Google сканирует сайты, чтобы находить зараженные ресурсы, фишинговые страницы и другие проблемы, которые ухудшают качество выдачи и пользовательский опыт. Благодаря этой информации поисковая система предупреждает пользователей о небезопасных сайтах. В случае, если сайт будет признан опасным, Google может понизить его в выдаче или удалить.
Дополнительная информация
- Панель веб-мастера Google
- Проверка Google Safe-browsing
Данные теста были получены 29.08.2021 05:15
Яндекс вирусы
Сайт безопасен.
Описание
Обычно заражение происходит из-за уязвимости, которая позволяет хакерам получить контроль над сайтом. Он может изменять содержание сайта или создавать новые страницы, обычно для фишинга. Хакеры могут внедрять вредоносный код, например скрипты или фреймы, которые извлекают содержимое с другого сайта для атаки компьютеров, на которых пользователи просматривают зараженный сайт.
Дополнительная информация
Панель веб-мастера Яндекс
Данные теста были получены 29.08.2021 05:15
PR-CY Rank
Рейтинг домена — 48 / 100
Ссылочное
Доверие
Трафик
По данному тесту найдена история!
В графике изменения за 5 месяцев (начиная с июнь 2020). Доступно на платных тарифах.
Тарифы и цены
Подробнее
Описание
PR-CY Rank — рейтинг для оценки перспективности сайтов в качестве доноров для линкбилдинга. При формировании рейтинга мы анализируем трафиковые и трастовые параметры, а также ссылочный профиль сайта.
Влияние — потенциал влияния сайта на продвижение. Если влияние слабое, то слабым будет как отрицательный эффект (если рейтинг низкий), так и положительный (если рейтинг высокий) и наоборот. Потенциал влияния основан на размере постоянной аудитории сайта.
Ссылочный фактор — вычисляется на основе соотношения входящих и исходящих ссылок на сайт, значений Trust Rank, Domain Rank и др.
Трафиковый фактор — вычисляется на основании объёма и динамики трафика (отрицательная динамика портит рейтинг, положительная динамика — повышает).
Трастовый фактор — анализирует множество параметров, таких как “ИКС”, доля поискового трафика в общем трафике, адаптацию под мобильные устройства и множество других факторов, признанных поисковыми системами, как значимые для ранжирования.
Данные теста были получены 29.08.2021 05:16

Категория сайта
Компьютеры, Электроника и Технологии
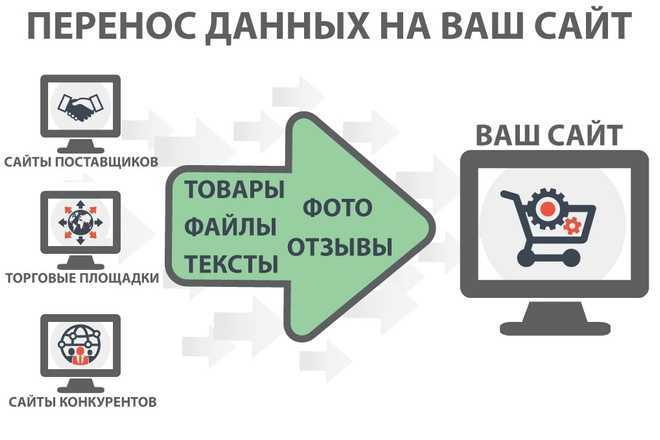
Почему и зачем использовать веб-парсинг?
Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
Динамический мониторинг цен
Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Bitcop
![]()
Работает на ОС: Windows XP, Vista, 7, 8, 10Бесплатный режим: полный функционал мониторинга 1 пользователя с облачным хранением данных Программа для комплексного мониторинга всех действий пользователей за компьютером
Многофункциональное ПО для отслеживания работы и действий юзера в период активности ПК. Программное обеспечение обладает широчайшим функционалом, работает тайно, в зависимости от настроек система может сообщать обо всех действиях человека. Есть функция keylogger , она фиксирует все нажатия клавиш на клавиатуре, также отслеживаются поисковые запросы и общение в мессенджерах. На основе полученных данные формируются наглядные отчеты, которые передаются через ftp в облако.
Эта шпионская программа для ПК может эффективно контролировать рабочее время специалистов на местах и фрилансеров. Она просматривает запуск приложений, поисковые запросы, сетевые ресурсы. Можно ограничить доступ к определенным сайтам и приложениям. В ответ на попытку несанкционированного или запрещенного действия программа для скрытого наблюдения за ПК блокирует это действие или отсылает отчет. Отчет формируется в конкретное время по заданным параметрам. Параметры и время задаете вы.
Программу для контроля активности ПК можно эффективно применять в небольших и крупных компаниях, она отлично подходит для наблюдения за компьютером фрилансера с целью отслеживания рабочего времени и формирования удобных наглядных отчетов. Бесплатный режим программы для слежения за компьютером можно использовать без ограничений для одного устройства.
- Ведет учет рабочего времени за ПК,
- Ведет анализ продуктивности,
- Сбор информации о использовании программ и вебсайтов,
- Логирование интернет запросов,
- Учитывает системные события,
- Скрытый режим работы,
- Скриншоты экрана,
- Тайм-трекинг.
Сравнительная таблица
| Название | Стоимость | Пробник | ЯзыкАнглийский (+)Русский (++) | Функционал |
| Mention | 29$ | + | + | Отслеживание упоминаний брендов |
| Hootsuite | 19$ | + | + | Отметки в соцсетях |
| Open Social Buzz | 3,49€ | + | + | Дает оценку аудитории, анализирует подписчиков и тексты |
| SimilarWeb | нужно уточнять | + | + | Общие SEO-показатели |
| XTool | – | + | ++ | Проверка траста |
| AHrefs | 99$ | + | ++ | Индексация, аналитика контента и SEO |
| Majestic | 49,99$ | + | +, ++ | Поиск по ключам, обратным ссылкам, сравнение профилей |
| LinkPad | 1450₽ | + | +, ++ | Полный SEO-аудит |
| Monitor Backlink | 25$ | + | + | Отслеживание шаринга контента, настройка фильтров по тегам, поиск по ключевикам |
| SpyWords | 1928₽ | + | ++ | Дает все ключи по поисковику и контексту |
| KeywordSpy | 89,95$ | + | + | Аналитика СЯ |
| SerpStat | 69$ | + | ++ | SEO-аудит |
| SEM Rush | 120$ | + | + | Более 40 полезных инструментов |
| MegaIndex | 2990₽ | + | ++ | Релевантность текста, входящие линки, индексация |
| BacklinkWatch | — | + | ++ | Проверка страниц с обратными ссылками |
| iSpionage | 59$ | + | + | Аналитика рекламных объявлений и SEO |
| Be1 | 7000₽ | + | ++ | Индексация, видимость, метатеги, ссылочная масса |
| GOOGLE ALERTS | — | + | + | Упоминания бренда |
| arsenkin | 3299₽ | + | ++ | Комплексная проверка SEO |
| СайтРепорт | 125₽ | + | ++ | Технический аудит, семантика |
| ПИКСЕЛЬ ТУЛС | 950₽ | + | ++ | Внутренняя и внешняя оптимизация |
| KEYS.SO | 1500₽ | + | ++ | Сбор ядра |
| Netpeak Spider | 26$ | + | + | SEO, парсинг |
| Букварикс | 695₽ | + | ++ | Подбор ключей |
| Топвизор | 999₽ | + | ++ | Полноценная аналитика для SEO |